CMS Site Log for PHOENIX Cluster
2. 4. 2007 Load Tests on new dCache SE
We brought the new dCache based SE into production by end of last week. The STAR-CSCS FTS channel hosted by FZK has now been extended to also allow transfers to the new SRM endpoint. The SRM transfer quality looks good, though the actual rate is not overwhelming. Only T1_ASGC transfers have problems and ther errors uniformly seem to indicate a problem on the T1 side. Statistics for the last 12 hours:
SITE STATISTICS:
==================
first entry: 2007-04-02 08:29:00 last entry: 2007-04-02 12:02:17
site: T1_FZK_Buffer (OK: 54 / Err: 0) succ. rate: 100.0 % total: 133.2 GB avg. rate: 6.4 MB/s = 53.8 Mb/s
site: T1_RAL_Buffer (OK: 1 / Err: 0) succ. rate: 100.0 % total: 2.6 GB avg. rate: 0.8 MB/s = 7.0 Mb/s
site: T1_ASGC_Buffer (OK: 0 / Err: 42) succ. rate: 0.0 % total: 0.0 GB
site: T1_FNAL_Buffer (OK: 9 / Err: 0) succ. rate: 100.0 % total: 24.6 GB avg. rate: 1.3 MB/s = 10.8 Mb/s
*** ERRORS from T1_ASGC_Buffer:***
42 Failed SRM get on httpg://castorsc.grid.sinica.edu.tw:8443/srm/managerv1 ;id=[id]call. Error is specified file(s) does
not exist
I can sometimes see that there are big transfers between the dCache pool nodes. Either a door on one node is actually saving a file on the other node or it is some kind of redistribution (probably the first, I guess). This waste of bandwidth is not optimal and should be studied.
3. 4. 2007 failing transfers, SLC4 nodes
The transfers of the last 12 hours look unanimously bad. All failed transfers except for ASGC show the same error: transfer expired in the download agent queue. This seems to be a PhEDEx problem. Based on a message of Chia Ming Kuo on the list the ASGC error is due to their migrationg from CASTOR to CASTOR2.
SITE STATISTICS:
==================
first entry: 2007-04-03 00:06:51 last entry: 2007-04-03 07:44:51
site: T1_FZK_Buffer (OK: 29 / Err: 386) succ. rate: 7.0 % total: 71.4 GB avg. rate: 1.9 MB/s = 16.2 Mb/s
site: T1_RAL_Buffer (OK: 25 / Err: 193) succ. rate: 11.5 % total: 64.1 GB avg. rate: 2.9 MB/s = 24.2 Mb/s
site: T1_ASGC_Buffer (OK: 0 / Err: 33) succ. rate: 0.0 % total: 0.0 GB
site: T1_FNAL_Buffer (OK: 20 / Err: 298) succ. rate: 6.3 % total: 54.8 GB avg. rate: 1.7 MB/s = 14.4 Mb/s
*** ERRORS from T1_FZK_Buffer:***
386 transfer expired in the download agent queue
We will try bring now the new SLC4 nodes into the system. This is problematic for CMS, because the new software area has not been set up correctly yet. Peter Elmer has notified us, that we would be a test site for this kind of operation.
5. 4. 2007 New PhEDEx FileDownload from CVS
I installed a new FileDownload version from CVS (Rev. 1.103), and this seems to have taken care of the many _transfer expired_ errors. But the amount of transfers and the rates are not very exciting:
SITE STATISTICS:
==================
first entry: 2007-04-05 05:15:25 last entry: 2007-04-05 11:18:35
site: T1_FZK_Buffer (OK: 14 / Err: 0) succ. rate: 100.0 % total: 34.6 GB avg. rate: 3.7 MB/s = 31.3 Mb/s
site: T1_RAL_Buffer (OK: 12 / Err: 0) succ. rate: 100.0 % total: 30.8 GB avg. rate: 3.0 MB/s = 25.2 Mb/s
site: T1_ASGC_Buffer (OK: 7 / Err: 3) succ. rate: 70.0 % total: 19.7 GB avg. rate: 1.0 MB/s = 8.4 Mb/s
site: T1_FNAL_Buffer (OK: 10 / Err: 0) succ. rate: 100.0 % total: 27.5 GB avg. rate: 1.4 MB/s = 12.1 Mb/s
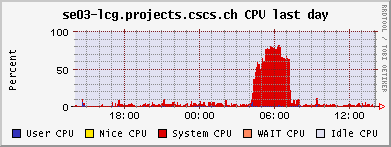
This morning one of our dCache pool nodes died. Seemingly just did not react any more, but the remote management still was working. Seemingly just at the time when the weekly disk scrubbing was running.
Tom restarted the scrubbing in the afternoon to see whether it's a persistent problem connected to it. But the run finished ok. So it is not clear what the problem was. There were no messages in the logs. Scrubbing takes place in the kernel, so a bad problem could show this behavior.
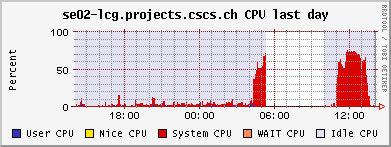

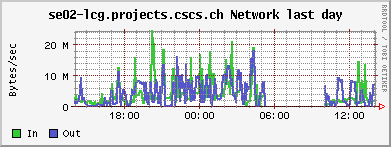
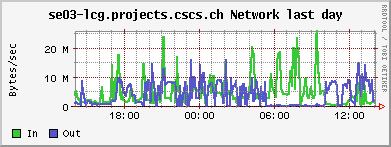
 The network load:
The network load:
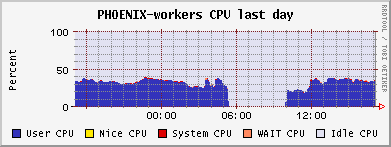
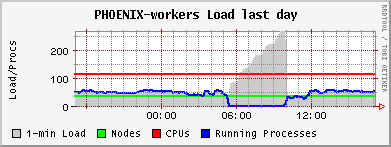
 The PhEDEx load tests continued to the still working pool node se03-lcg. But the failure had a major impact on the worker nodes:
The PhEDEx load tests continued to the still working pool node se03-lcg. But the failure had a major impact on the worker nodes:


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
cpu_report-se02-lcg20070405-1404.gif | r1 | manage | 12.0 K | 2007-04-05 - 12:36 | DerekFeichtinger | |
| |
cpu_report-se03-lcg20070405-1404.gif | r1 | manage | 11.6 K | 2007-04-05 - 12:37 | DerekFeichtinger | |
| |
load_report-se02-lcg20070405-1404.gif | r1 | manage | 11.8 K | 2007-04-05 - 12:37 | DerekFeichtinger | |
| |
load_report-se03-lcg20070405-1404.gif | r1 | manage | 11.1 K | 2007-04-05 - 12:37 | DerekFeichtinger | |
| |
network_report-se02-lcg20070405-1404.gif | r1 | manage | 13.5 K | 2007-04-05 - 12:38 | DerekFeichtinger | |
| |
network_report-se03-lcg20070405-1404.gif | r1 | manage | 13.4 K | 2007-04-05 - 12:38 | DerekFeichtinger | |
| |
worker-CPU.gif | r1 | manage | 11.1 K | 2007-04-05 - 15:05 | DerekFeichtinger | |
| |
worker-load.gif | r1 | manage | 10.7 K | 2007-04-05 - 15:06 | DerekFeichtinger |
Topic revision: r4 - 2007-04-05 - DerekFeichtinger

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback