Service Card for dCache
dCache is our mass Grid Storage resource. It serves more than 1 Petabyte of space to all VOs, mainly using GridFTP and dcap access protocols.
Definition
This is the list of nodes with related dCache services:
| Nodes |
Services hosted |
| storage01 |
srm, utility, httpd, info, gridftp, dcap, BDII |
| storage02 |
lm, dCache, gPlazma, chimera, chimera-nfs, dir, admin |
| se[01-10,13-22] |
gridftp |
| se[01-10,13-22] |
pool |
Please note that the only dependency is that
storage01 (srm) needs to have /pnfs mounted from storage02 (chimera-nfs)
This page shows the space reservations in place (currently a bit obsolete):
Dcache_SpaceTokens_sm
The most up to date information can be found in the
dCache web interface
Hardware overview:
- Head nodes storage[01-02] are installed on IBM hardware. SL 6.x x86_64 with dCache 2.6.x series. IB IB stack
- There are two types of storage pools:
- se[01-08] are IBM hosts connected to IBM DC3500 controllers configured with SL 5.x x86_64, dCache 2.6 series, Mellanox IB packages and mpp for fibrechannel multipath. There is one FC card per host connected to the two channels of the IBM DC3500 controller.
- se[09-16] are IBM hosts connected to IBM DCS3700 controllers. SL 6.x, dCache 2.6, SL IB and multipath packages.
- se[17-22] are IBM or HP hosts connected to NetApp controllers. SL 6.x, dCache 2.6, SL IB and multipath packages.
Operations
Client tools
There are several ways to connect to dCache internal interface. Using the graphical pcells:
- You can run the GUI (pcells) If you have good bandwidth with pub or ui64, by ssh-ing into it (as a user) and run
dcache-gui. The first time you need to configure a new connection to storage02.
- Alternatively, you can run pcells in your desktop, configure it to connect to
localhost, and first create a tunnel through pub: ssh user@pub.lcg.cscs.ch -L 22223:storage02:22223
Or shell-based console
- To be able to access the ssh shell console in dCache, you need to connect to it with:
ssh -2 admin@storage02 -i /usr/libexec/nagios-plugins/.ssh/ssh_host_dsa_key -p 22224
- You can use Derek's DcacheShellutils
For the shell-based console, you can use a password, or an ssh1 key pair and copy it to cfengine controlled special dCache authorized_keys. The process is described here:
http://trac.dcache.org/projects/dcache/wiki/manuals/admin_interface
Working with space reservations
- Note: Space displayed in the web interface is shown as MiB whereas when using the SSH interface it appears to be listed in bytes. As show in later commands when performing updates it is possible to specify units.
- 1Mib = 1.04858MB
- Documentation for the commands used with reservations can be found by running
help inside the SrmSpaceManager cell.
- If you want to see the space tokens in the system with detailed information you need to perform an 'ls' in the SrmSpaceManager, e.g.
[storage02.lcg.cscs.ch] (local) admin > cd SrmSpaceManager
[storage02.lcg.cscs.ch] (SrmSpaceManager) admin > ls
Reservations:
34718295 voGroup:/lhcb voRole:null retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:0 size:0 created:Wed Jun 19 14:43:49 CEST 2013 lifetime:-1ms expiration:NEVER description:LHCb_USER state:RESERVED used:0 allocated:0
223 voGroup:/atlas voRole:production retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:4 size:780000000000000 created:Tue Feb 19 10:33:10 CET 2008 lifetime:-1ms expiration:NEVER description:ATLASDATADISK state:RESERVED used:670321496694602 allocated:0
54172751 voGroup:/cms voRole:priorityuser retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:2 size:663107670 created:Tue Sep 30 10:42:53 CEST 2014 lifetime:2399985ms expiration:Tue Sep 30 11:22:53 CEST 2014 description:null state:RESERVED used:0 allocated:663107670
1941364 voGroup:atlas/ch voRole:null retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:10000000000000 created:Tue Sep 09 14:02:26 CEST 2008 lifetime:-1ms expiration:NEVER description:ATLASLOCALGROUPDISK state:RESERVED used:8322044239556 allocated:0
1631505 voGroup:atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:10000000000000 created:Fri Jul 18 12:09:44 CEST 2008 lifetime:-1ms expiration:NEVER description:ATLASPRODDISK state:RESERVED used:4919552759109 allocated:3551320456
222 voGroup:/atlas voRole:production retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:4 size:100000000000 created:Tue Feb 19 10:31:56 CET 2008 lifetime:-1ms expiration:NEVER description:ATLASMCDISK state:RESERVED used:39394445860 allocated:0
34718259 voGroup:/lhcb voRole:null retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:0 size:230000000000000 created:Wed Jun 19 14:41:05 CEST 2013 lifetime:-1ms expiration:NEVER description:LHCb-Disk state:RESERVED used:85891952795361 allocated:0
3205575 voGroup:/atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:38000000000000 created:Mon Apr 06 15:14:02 CEST 2009 lifetime:-1ms expiration:NEVER description:ATLASSCRATCHDISK state:RESERVED used:17218172543300 allocated:0
total number of reservations: 8
total number of bytes reserved: 1068100663107670
- To show only the reservations for a specific link group
[storage02.lcg.cscs.ch] (SrmSpaceManager) admin > ls -lg=atlas-linkGroup
Found LinkGroup:
4 Name:atlas-linkGroup FreeSpace:137832997369994 ReservedSpace:137260646735722 AvailableSpace:572350634272 VOs:{atlassgm:*}{/atlas:*}{/atlas/lcg1:*}{altasprd:*}{/atlas/ch:*}{atlas001:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Tue Sep 30 11:07:30 CEST 2014(1412068050125)
223 voGroup:/atlas voRole:production retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:4 size:780000000000000 created:Tue Feb 19 10:33:10 CET 2008 lifetime:-1ms expiration:NEVER description:ATLASDATADISK state:RESERVED used:670321496694602 allocated:0
222 voGroup:/atlas voRole:production retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:4 size:100000000000 created:Tue Feb 19 10:31:56 CET 2008 lifetime:-1ms expiration:NEVER description:ATLASMCDISK state:RESERVED used:39394445860 allocated:0
1941364 voGroup:atlas/ch voRole:null retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:10000000000000 created:Tue Sep 09 14:02:26 CEST 2008 lifetime:-1ms expiration:NEVER description:ATLASLOCALGROUPDISK state:RESERVED used:8322044239556 allocated:0
3205575 voGroup:/atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:38000000000000 created:Mon Apr 06 15:14:02 CEST 2009 lifetime:-1ms expiration:NEVER description:ATLASSCRATCHDISK state:RESERVED used:17218298580729 allocated:0
1631505 voGroup:atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:10000000000000 created:Fri Jul 18 12:09:44 CEST 2008 lifetime:-1ms expiration:NEVER description:ATLASPRODDISK state:RESERVED used:4938119303531 allocated:14892375
- To create a new token perform in the same Cell:
- Syntax is as follows; reserve [-vog=voGroup] [-vor=voRole] [-acclat=AccessLatency] [-retpol=RetentionPolicy] [-desc=Description] [-lgid=LinkGroupId] [-lg=LinkGroupName]
- The below example creates a reservation for 10TB under link group "atlas-linkGroup" that will not expire due to the "-1" lifetime which mean infinite.
reserve -vog=/atlas -vor=production -lg=atlas-linkGroup -acclat=ONLINE -retpol=OUTPUT -desc=ATLASPRODDISK 10TB "-1"
- To increase the size of a token (aka set the new max size), note the "222" is the id of the reservation we intend to update.
update space reservation -size=15TB 222
Example for Swiss users
- ATLAS: We need to increase the ATLASLOCALGROUPDISK (ID 1941364) reservation by 150TB, it already exists as a 10TB reservation so we need to update its space to 160TB
update space reservation -size=160TB 1941364
- CMS: There are no space reservations for CMS, however CH users can be identified with the "/cms/chcms" attribute.
reserve -vog=/cms/ch -vor=chcms -lg=cms-linkGroup -acclat=ONLINE -retpol=OUTPUT -desc=CHCMS 150TB "-1"
- LHCb: As LHCb can't easily distinguish CH users we just need to update the LHCb-Disk (ID 34718259) reservation. This was 230TB and we are adding 60TB
update space reservation -size=290TB 34718259
Testing
There are two tools installed in ui64 to test dCache. They are in the path (/opt/cscs/bin) and you need a valid grid proxy to use them.
- chk_SE-dcache. It tests the basic grid protocols with non-lcg tools, like gridftp, dccp and srmcp. It does not depend on external tools like the LFC or the BDII.
- chk_SE-lcgtools. It performs more complicated operations, using lcg-* tools. It requires proper BDII publishing and access to the LFC at CERN/FZK.. It also checks space tokens (with -t)
Start/stop procedures
- service dcache.This is the basic dcache (link to /opt/d-cache/bin/dcache) and can be used for most operations. It is automatically started on boot. For example, you can restart all services in one host with
service dcache restart or only one of the services with service dcache restart gPlazma
There is a more detailed document about a Full restart here:
DcacheFullRestart
Adding new pools
- Create the arrays and mountpoints
- Create the pools as follows (showing an example of a 30T system with 2 pools for ATLAS):
Jul 15 14:40 [root@se18:~]# for i in 6 7; do echo dcache pool create --size=31990000000000 /data_phaseH_storage_r6_1_18_array${i}/pool data_phaseH_storage_r6_1_18_array${i}_atlas data_phaseH_storage_r6_1_18_array${i}_atlas; done
- Make sure the file
storage01:/etc/dcache/layouts/${HOSTNAME}.conf is correct and put into Configuration Management Software
- Add the pools to the corresponding pool groups and pool Linkgroups on
storage01:/var/lib/dcache/config/poolmanager.conf
- Reload the pool list using dCache interface
Checking logs
Please go to /var/log/dcache/ to find relevant logs.
Chimera migration
This procedure is already done, and not really necessary anymore. Check
ChimeraMigration
Solaris to Linux migration
This procedure is already done, and not really necessary anymore. Check
SolarisToLinuxMigrationDcache
Dealing with File Loss
Normally, file loss is not a terrible loss. You need to inform about this, and hopefully they can be able to give you back the files.
- Prepare a pnfs name list of the lost files and send this list to the site contacts. They responsible to take it from there to his experiment.
- reestablish dcache/pnfs consistency by deleting leftover pnfs names with no on-site replicas.
- SQL to obtain pnfsids for files on one pool that are only in that pool (to see what's lost):
select ipnfsid, from t_locationinfo where ipnfsid in (select ipnfsid from t_locationinfo where ilocation='ibm01_data1_cms') group by ipnfsid having (count(ilocation) = 1);
- SQL to delete the trash table (deletions on pools) after doing a massive RM on the /pnfs tree.
delete from t_locationinfo_trash where ilocation='ibm01_data1_cms';
CMS site contacts:
- Follow this procedure written by Leo for the central CERN wiki in order to map the files to data sets, and delete the replica information from the phedex DB.
Migrate data out of a set of pools.
- You probably want start with the default configuration before touching things
cd PoolManager
reload -yes
- In dCache pcells interface, set a pool read-only:
cd PoolManager
psu set pool se12_cms rdonly
- Create a special group of pools to use as a target for migration. Check below for the whole list
cd PoolManager
psu create pgroup cms_migration
psu addto pgroup cms_migration se31_cms
- In dCache pcells interface, start migration of data out of that pool
cd se12_cms
migration move -target=pgroup -concurrency=5 cms_migration
- Another option here is to migrate data of a specific VO off a certain pool with this:
migration move -target=pgroup -storage=cms:cms -concurrency=4 pgroup_of_CMS_pools
- Check the state of the migration
migration info 1
- You may want to disable the gridftp door on that node, so that, at the end of the migration, you can just shut down the dcache service.
cd LoginBroker
disable GFTP-se12
- Before shutting down the pool, you may want to verify that dCache is not aware of any file that could be left inside the pool - there are always some inconsistencies. You can check this asking the chimera node:
[root@storage02:~]# psql chimera -U chimera -c "select count(*) from t_locationinfo where ilocation='se15_cms';"
Enable/Disable a door
$ ssh phoenix1
$ ssh -l admin -p 22224 storage02.lcg.cscs.ch
cd LoginBroker
disable GFTP-se18
disable GFTP-se17
Change the number of transfers (movers) that a door accepts
$ export DCACHE_NUM_MOVERS_DOOR=300
$ echo -e 'cd PoolManager\npsu ls pool\n..\nlogoff\n' | ssh -l admin -p 22224 storage02.lcg.cscs.ch 2>&1 | grep data_ | tr -d $'\r' &> /tmp/pools
$ for pool in $(cat /tmp/pools); do echo "cd ${pool}"; echo "mover set max active ${DCACHE_NUM_MOVERS_DOOR} -queue=regular"; echo ".."; done | ssh -l admin -p 22224 storage02.lcg.cscs.ch 2>&1
Move a set of pools to a different dCache server
Sometimes it is required to move pools from a machine (A) to another system (B) to do tasks such as HW maintenance. This is a relatively easy task with little downtime.
- Disable the door running on A as shown before
- Stop dCache on A
# dcache stop
- Umount the Logical Volumes to move on A
# umount /data_phaseG_storage_10_array0 # umount /data_phaseG_storage_10_array1 # umount /data_phaseG_storage_10_array2
- On A comment out the mounts on
/etc/fstab
- On B add the mounts to
/etc/fstab
-
Stop cfengine on B ('service cfexecd stop' and 'service cfenvd stop')
- On B edit the option 'volume_list' in /etc/lvm/lvm.conf adding the storage from host A
- Deactivate the Logical Volumes on A
# lvchange -a n phaseG_storage_10_array0 phaseG_storage_10_array1 phaseG_storage_10_array2
- Make sure volumes can be seen by B by running
# multipath -ll
- Activate the Logical Volumes deactivated before, on server B
# lvchange -a y phaseG_storage_10_array0 phaseG_storage_10_array1 phaseG_storage_10_array2
- Make sure the correct mount points exist on B
- Mount the volumes with
# mount -a
- Copy the proper entries of
/etc/dcache/layouts/A.conf to /etc/dcache/layouts/B.conf
- Start all pools in dcache on B.
# dcache start
List the files on a Space Token
Connect to the
SrmSpaceManager and issue the following commands:
- Find out which is the ID of the Space Token you want (first column under Reservations):
# ls
Reservations:
3205575 voGroup:/atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:28000000000000 created:Mon Apr 06 15:14:02 CEST 2009 lifetime:-1ms expiration:NEVER description:ATLASSCRATCHDISK state:RESERVED used:21799242579873 allocated:0
222 voGroup:/atlas voRole:production retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:4 size:100000000000 created:Tue Feb 19 10:31:56 CET 2008 lifetime:-1ms expiration:NEVER description:ATLASMCDISK state:RESERVED used:39394445860 allocated:0
4254214 voGroup:/atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:50000000000000 created:Wed Sep 16 16:21:31 CEST 2009 lifetime:-1ms expiration:NEVER description:ATLASGROUPDISK state:RESERVED used:1322228694829 allocated:0
1631505 voGroup:atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:10000000000000 created:Fri Jul 18 12:09:44 CEST 2008 lifetime:-1ms expiration:NEVER description:ATLASPRODDISK state:RESERVED used:1831550835057 allocated:0
1941364 voGroup:atlas/ch voRole:null retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:10000000000000 created:Tue Sep 09 14:02:26 CEST 2008 lifetime:-1ms expiration:NEVER description:ATLASLOCALGROUPDISK state:RESERVED used:3490336858842 allocated:0
223 voGroup:/atlas voRole:production retentionPolicy:REPLICA accessLatency:ONLINE linkGroupId:4 size:710000000000000 created:Tue Feb 19 10:33:10 CET 2008 lifetime:-1ms expiration:NEVER description:ATLASDATADISK state:RESERVED used:605825455405365 allocated:0
4254201 voGroup:/atlas voRole:production retentionPolicy:OUTPUT accessLatency:ONLINE linkGroupId:4 size:3000000000000 created:Wed Sep 16 16:20:39 CEST 2009 lifetime:-1ms expiration:NEVER description:ATLASHOTDISK state:RESERVED used:1060540539738 allocated:0
total number of reservations: 7
total number of bytes reserved: 811100000000000
LinkGroups:
3 Name:dteam-linkGroup FreeSpace:20008531276 ReservedSpace:0 AvailableSpace:20008531276 VOs:{dteamsgm:*}{/dteam:*}{dteam001:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
1 Name:dech-linkGroup FreeSpace:21474667014 ReservedSpace:0 AvailableSpace:21474667014 VOs:{dechsgm:*}{/dech:*}{dechprd:*}{dech001:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
5 Name:ops-linkGroup FreeSpace:42949660822 ReservedSpace:0 AvailableSpace:42949660822 VOs:{/ops/NGI/Germany:*}{opssgm:*}{/ops:*}{opsprd:*}{ops001:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
6 Name:hone-linkGroup FreeSpace:313104425916 ReservedSpace:0 AvailableSpace:313104425916 VOs:{/hone:*}{honeprd:*}{honesgm:*}{hone001:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
4 Name:atlas-linkGroup FreeSpace:178634678467080 ReservedSpace:175731250640436 AvailableSpace:2903427826644 VOs:{atlassgm:*}{/atlas:*}{/atlas/lcg1:*}{altasprd:*}{/atlas/ch:*}{atlas001:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
0 Name:lhcb-linkGroup FreeSpace:1288458125084 ReservedSpace:0 AvailableSpace:1288458125084 VOs:{lhcb001:*}{lhcbsgm:*}{lhcbprd:*}{/lhcb:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
2 Name:cms-linkGroup FreeSpace:252388091630454 ReservedSpace:0 AvailableSpace:252388091630454 VOs:{cms001:*}{cmssgm:*}{/cms/itcms:*}{/cms:*}{cmsprd:*} onlineAllowed:true nearlineAllowed:false replicaAllowed:true custodialAllowed:false outputAllowed:true UpdateTime:Fri Apr 12 14:03:42 CEST 2013(1365768222283)
total number of linkGroups: 7
total number of bytes reservable: 256977514867210
total number of bytes reserved : 175731250640436
last time all link groups were updated: Fri Apr 12 14:03:42 CEST 2013(1365768222283)
- For the specified Space Token ID, issue this command (assuming id is
4254214): # listFilesInSpace 4254214
21196092 /atlas production 4254214 20 1339879906842 119991 /pnfs/lcg.cscs.ch/atlas/atlasgroupdisk/SAM/testfile-put-ATLASGROUPDISK-1339879765-0d8b925d623c.txt 0000FB317A1A58F7420481C01EA74176DBCF Stored 0
7991666 /atlas production 4254214 242835872 1287175575623 14399992 /pnfs/lcg.cscs.ch/atlas/atlasgroupdisk/perf-egamma/data10_7TeV/NTUP_TRT/f295_p246/data10_7TeV.00166658.physics_Egamma.merge.NTUP_TRT.f295_p246_tid177325_00/NTUP_TRT.177325._000020.root.1 0000D11E14AF004B4BE9A0DAD90351DCDFE4 Stored 0
[...]
Removing and modifying space tokens
Find the space token size and ID
cd SrmSpaceManager
ls
Ensure no files are present
listFilesInSpace 4254201
Remove the space token
release 4254201
After waiting for at least 30 minutes add the free space to another token. The size is the total size for the space token (add freed to old existing space).
update space reservation -size=703000000000000 223
ATLAS FAX
The ATLAS FAX service depends of two elements:
If either of both is not working, the system will show RED status in the
ATLAS FAX monitoring page for CSCS.
Reference:
https://twiki.cern.ch/twiki/bin/view/AtlasComputing/FAXdCacheN2Nstorage
Note: Please note that the certificate in
/etc/grid-security/xrd/xrdcert.pem
needs to be equal to the one in
/etc/grid-security/hostcert.pem
Set up
Installation (kept for historical reasons)
You need to perform some steps, some taken from
http://www.dcache.org/manuals/Book/start/in-install.shtml
- After the installation, you need to install postgres 8.3 by hand but first make use there is a separate partition for /var/lib/pgsql:
lvcreate -L 55G -n lv_pgsql vg_root
mkfs.ext3 /dev/vg_root/lv_pgsql
mv /var/lib/pgsql /var/lib/pgsql.backup
mkdir /var/lib/pgsql
echo '/dev/vg_root/lv_pgsql /var/lib/pgsql ext3 defaults 1 2' >> /etc/fstab
mount -a
chmod 700 /var/lib/pgsql
chown postgres.postgres /var/lib/pgsql
cp -a /var/lib/pgsql.backup/. /var/lib/pgsql/
rpm -e --nodeps postgresql-libs.x86_64 postgresql-libs.i386
rpm -U ftp://ftp.postgresql.org/pub/binary/v8.3.9/linux/rpms/redhat/rhel-5-x86_64/compat-postgresql-libs-4-1PGDG.rhel5.x86_64.rpm \
ftp://ftp.postgresql.org/pub/binary/v8.3.9/linux/rpms/redhat/rhel-5-x86_64/postgresql-8.3.9-1PGDG.rhel5.x86_64.rpm \
ftp://ftp.postgresql.org/pub/binary/v8.3.9/linux/rpms/redhat/rhel-5-x86_64/postgresql-libs-8.3.9-1PGDG.rhel5.x86_64.rpm \
ftp://ftp.postgresql.org/pub/binary/v8.3.9/linux/rpms/redhat/rhel-5-x86_64/postgresql-server-8.3.9-1PGDG.rhel5.x86_64.rpm \
ftp://ftp.postgresql.org/pub/binary/v8.3.9/linux/rpms/redhat/rhel-5-i386/compat-postgresql-libs-4-1PGDG.rhel5.i686.rpm
# yum install postgresql-server compat-postgresql-libs.i686 compat-postgresql-libs.x86_64
service postgresql initdb
sed -i 's/ident sameuser/trust/' /var/lib/pgsql/data/pg_hba.conf
service postgresql restart
createuser -U postgres --no-superuser --no-createrole --createdb srmdcache
createdb -U srmdcache dcache
createdb -U srmdcache billing
- Prepare chimera in the right node (Node02)
createdb -U postgres chimera
createuser -U postgres --no-superuser --no-createrole --createdb chimera
psql -U chimera chimera -f /opt/d-cache/libexec/chimera/sql/create.sql
createlang -U postgres plpgsql chimera
psql -U chimera chimera -f /opt/d-cache/libexec/chimera/sql/pgsql-procedures.sql
echo "/ localhost(rw)
/pnfs *.lcg.cscs.ch(rw)" > /etc/exports
### We create the basics
/opt/d-cache/libexec/chimera/chimera-cli.sh Mkdir /pnfs
/opt/d-cache/libexec/chimera/chimera-cli.sh Mkdir /pnfs/lcg.cscs.ch
echo "chimera" | /opt/d-cache/libexec/chimera/chimera-cli.sh Writetag /pnfs/lcg.cscs.ch sGroup
echo "StoreName sql" | /opt/d-cache/libexec/chimera/chimera-cli.sh Writetag /pnfs/lcg.cscs.ch OSMTemplate
ln -s /opt/d-cache/libexec/chimera/chimera-nfs-run.sh /etc/init.d/chimera-nfs
service chimera-nfs start
# You should be able to mount it from outside with: mount storage22.lcg.cscs.ch:/pnfs /pnfs
### If we want we can populate the VO dirs:
mount localhost:/ /mnt
cd /mnt/pnfs/lcg.cscs.ch
for i in atlas cms dech dteam hone lhcb ops; do
mkdir $i
chmod 775 $i
chown ${i}001.$i $i
echo "StoreName $i" > ./$i/".(tag)(OSMTemplate)"
echo "$i" > ./$i/".(tag)(sGroup)"
echo "OUTPUT" > ./$i/".(tag)(RetentionPolicy)"
echo "ONLINE" > ./$i/".(tag)(AccessLatency)"
done
### And finally:
cd
umount /mnt
Pool creation
- Using the dcache layouts templates, create the pools. Here is an example:
# cat layouts/se14.conf
[gridftp-se14Domain]
[gridftp-se14Domain/gridftp]
[data_phaseG_storage_10_array0_cms]
[data_phaseG_storage_10_array0_cms/pool]
name=data_phaseG_storage_10_array0_cms
path=/data_phaseG_storage_10_array0/pool
waitForFiles=${path}/data
lfs=precious
[data_phaseG_storage_10_array2_cms]
[data_phaseG_storage_10_array2_cms/pool]
name=data_phaseG_storage_10_array2_cms
path=/data_phaseG_storage_10_array2/pool
waitForFiles=${path}/data
lfs=precious
[data_phaseG_storage_10_array4_cms]
[data_phaseG_storage_10_array4_cms/pool]
name=data_phaseG_storage_10_array4_cms
path=/data_phaseG_storage_10_array4/pool
waitForFiles=${path}/data
lfs=precious
Add pools, obviously replace $VO and $N with whatever is applicable as well as storage name. Double check this before adding.
#Once the layout files are added
ssh storage01
ssh -2 admin@storage02 -i /usr/libexec/nagios-plugins/.ssh/ssh_host_dsa_key -p 22224
(local) admin > cd PoolManager
(PoolManager) admin > psu create pool data_phaseH_storage_14_array_$N_$VO
(PoolManager) admin > psu addto pgroup $VO data_phaseH_storage_14_array_$N_$VO
(PoolManager) admin > save
- Once this is done, do not forget to assign each of these pools a maximum capacity (
set max diskspace) or dCache will not compute well the available space: # cat /data_phaseG_storage_5_array1/pool/setup
#
# Created by data_phaseG_storage_5_array1_atlas(Pool) at Tue Jan 15 11:00:29 CET 2013
#
csm set checksumtype ADLER32
csm set policy -frequently=off
csm set policy -onread=off -onwrite=on -onflush=off -onrestore=off -ontransfer=off -enforcecrc=on -getcrcfromhsm=off
#
# Flushing Thread setup
#
flush set max active 1000
flush set interval 60
flush set retry delay 60
#
# HsmStorageHandler2(org.dcache.pool.classic.HsmStorageHandler2)
#
rh set max active 0
st set max active 0
rm set max active 1
rh set timeout 14400
st set timeout 14400
rm set timeout 14400
jtm set timeout -queue=regular -lastAccess=0 -total=0
jtm set timeout -queue=p2p -lastAccess=0 -total=0
jtm set timeout -queue=wan -lastAccess=0 -total=0
jtm set timeout -queue=io -lastAccess=0 -total=0
set heartbeat 30
set report remove on
set breakeven 0.7
set gap 4294967296
set duplicate request none
mover set max active -queue=regular 100
mover set max active -queue=p2p 10
mover set max active -queue=wan 10
#
# MigrationModule
#
#
# Pool to Pool (P2P) [$Revision: 1.61 $]
#
pp set port 0
pp set max active 10
pp set pnfs timeout 300
set max diskspace 23992761057280
- NOTE: Keep in mind that there is one domain per dCache pool, which creates a java process per domain. This affects the available memory for each java process. For example, on a machine with 64GB of RAM and 6 pools, you would have this:
# free -m
total used free shared buffers cached
Mem: 64402 59502 4899 0 3 50833
-/+ buffers/cache: 8665 55736
Swap: 16383 0 16383
# df |grep data_phaseG
23435843584 17307245868 6128597716 74% /data_phaseG_storage_5_array0
23435843584 18500647744 4935195840 79% /data_phaseG_storage_5_array1
23435843584 18531993564 4903850020 80% /data_phaseG_storage_5_array2
23435843584 17422559744 6013283840 75% /data_phaseG_storage_5_array3
23435843584 17864687500 5571156084 77% /data_phaseG_storage_5_array4
23435843584 17771529276 5664314308 76% /data_phaseG_storage_5_array5
# grep java.memory /opt/d-cache/etc/dcache.conf
dcache.java.memory.heap=4096m
dcache.java.memory.direct=4096m
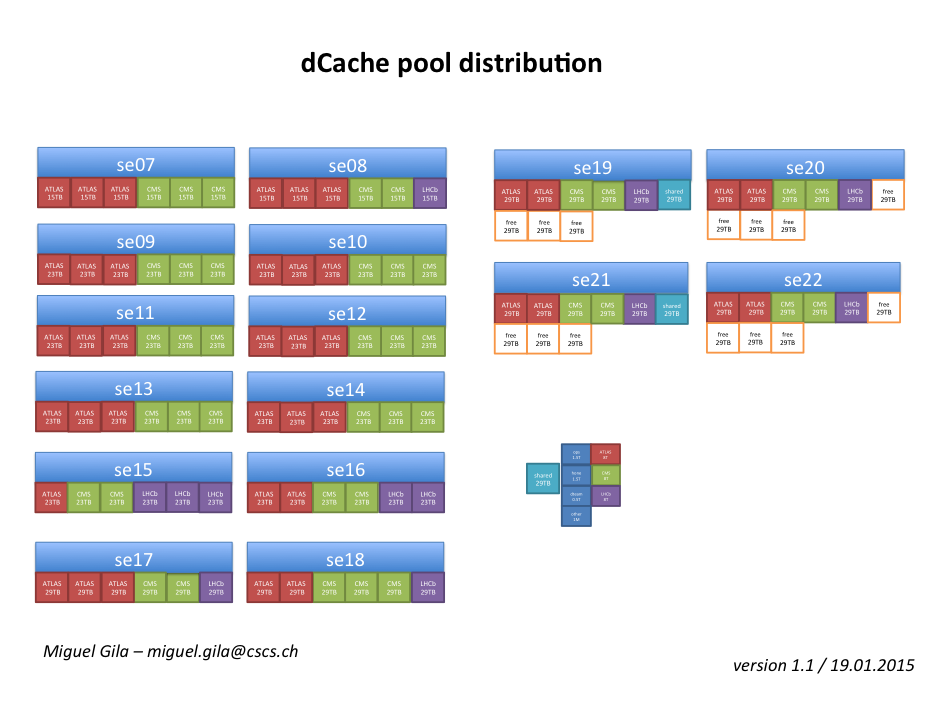
Pool distribution
This is the current pool distribution across the dCache instance:
Config files
Below is a litsing of common dcache configuration files and a brief overview of their function and syntax. For more details please the the full documentation on the dcache website
http://www.dcache.org/manuals/index.shtml
Default values can be found under /usr/share/dcache/defaults some examples are also found in /usr/share/dcache/examples
dcache.conf
The main configuration file for dcache, you should not have to edit this unless you are making a major change
Example
chimera.db.user = postgres
logback.xml
This file controls the default logging for dcache and is makes use of XML syntax. Note logging can be altered on the fly within the dcache cli so this may not reflect the current logging of a running system.
http://www.dcache.org/manuals/Book-2.6/config/cf-tss-monitor-fhs.shtml
<threshold>
<appender>pinboard</appender>
<logger>root</logger>
<level>info</level>
</threshold>
This file specifies the link group and who has permission to it.
http://www.dcache.org/manuals/Book-2.6/config/cf-write-token-spacereservation-fhs.shtml

Example below is taken from production, need to clarify syntax
LinkGroup cms-linkGroup
/cms
/cms/itcms
/cms/uscms
cmssgm
cmsprd
cms001
gplazma.conf
Controls what methods are valid for authentication. This file has a similar syntax to PAM files
http://www.dcache.org/manuals/Book-2.6/config/cf-gplazma-setup-fhs.shtml
Example
# step modifier plugin params k=v
auth optional x509
map requisite authzdb authzdb=/etc/grid-security/authzdb
layouts/*.conf
These files are host specific. In the case of storage01/ storage02 they control the dcache services that are run, for the SE machines they denote which pools are available.
Storage01 snippet
[srm-storage01Domain]
[srm-storage01Domain/srm]
srmJettyThreadsMax=1500
srmJettyThreadsMaxQueued=1500
srmCopyReqThreadPoolSize=2000
remoteGsiftpMaxTransfers=2000
SE snippet
[se01Domain_ibm01_data1_cms]
[se01Domain_ibm01_data1_cms/pool]
name=ibm01_data1_cms
path=/data1/cms
waitForFiles=${path}/setup
lfs=precious
Storage01 cells
Storage01 runs the following
- dcap-storage01Domain
- gridftp-storage01Domain
- utilityDomain
- httpdDomain
- infoDomain
- srm-storage01Domain
- xrootd-storage01Domain (port 1094)
- xrootd-CMS-Domain (port 1096)
- xrootd-CMS-Domain2 (port 1095)
- webdav-storage01Domain
Storage02 cells
- dCacheDomain
- gPlazma-storage02Domain running
- namespaceDomain
- dirDomain
- adminDoorDomain
- nfs-storage02Domain
OS notes
se[01-08] (mpp multipath module)
On a
Storage Element (pool), NOT on a Head Node, after the new kernel has booted, we need to do the following:
- Disconnect ONE of the FC cables BEFORE YOU BOOT so the OS sees only one path to the storage controllers.
- recreate the mpp rdac files:
# cd /root/linuxrdac-09.03.0C05.0331
# make uninstall
# make install
- This should create a mpp initrd file on /boot/ for the current booted kernel:
# ls -l /boot/mpp*
-rw------- 1 root root 4075301 Jan 27 2011 /boot/mpp-2.6.18-128.29.1.el5.img
-rw------- 1 root root 4165199 May 10 11:38 /boot/mpp-2.6.18-274.12.1.el5.img
- Now you need to change the
grub.conf file to boot next time using the mpp initrd created: # cat /boot/grub/grub.conf
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You have a /boot partition. This means that
# all kernel and initrd paths are relative to /boot/, eg.
# root (hd0,0)
# kernel /vmlinuz-version ro root=/dev/vg_root/lv_root
# initrd /initrd-version.img
#boot=/dev/sda
default=0
timeout=5
splashimage=(hd0,0)/grub/splash.xpm.gz
hiddenmenu
title Scientific Linux SL (2.6.18-308.8.2.el5)
root (hd0,0)
kernel /vmlinuz-2.6.18-308.8.2.el5 ro root=/dev/vg_root/lv_root rhgb
initrd /initrd-2.6.18-308.8.2.el5.img
title Scientific Linux SL (2.6.18-274.12.1.el5)
root (hd0,0)
kernel /vmlinuz-2.6.18-274.12.1.el5 ro root=/dev/vg_root/lv_root rhgb
initrd /mpp-2.6.18-274.12.1.el5.img
- Reboot the machine and connect the FC cable previously disconnected.
se[09-22] (SL6x standard multipath module)
These machines are SL6 with standard multipath and
infiniband packages from the distribution. This allows us to be able to update the kernel and or the system packages without worrying about compiling anything else. Just the standard
yum update should work fine.
yum install device-mapper-multipath lssci sg3_utils
chkconfig multipathd on
cfagent -qv #to get multipath.conf
reboot
A number of modifications have been done to these machines in order to make operations as smooth as possible:
-
/etc/multipath.conf has been configured to name the arrays properly, based on the WWID of each of them: multipath {
wwid 360080e50002ddd4c0000053c50766586
alias phaseG_storage_7_array0
} for more details about how to find arrays' WWIDs on IBM storage systems please refer to this page
-
/etc/multipath.conf blacklists the machine's own RAID controller: blacklist {
device {
product "ServeRAID M5110e"
}
}
- a LVM Physical Volume (PV) has to be created on each device associated with a logical array on the storage system:
[root@se15:~]# for i in $(seq 1 5); do pvcreate /dev/mapper/phaseH_storage_11_array${i}; done
[root@se16:~]# for i in $(seq 1 5); do pvcreate /dev/mapper/phaseH_storage_12_array${i}; done
and then a LVM Volume Group (VG) must be created for each storage system belonging to a storage server and including all the respective PV created in the previous step (in the example Storage11 belongs to se15 and Storage16 belongs to se16:
[root@se15:~]# vgcreate phaseH_storage_11 /dev/mapper/phaseH_storage_11_array*
[root@se16:~]# vgcreate phaseH_storage_12 /dev/mapper/phaseH_storage_12_array*
At this point a Logical Volume (LV) can be defined for each logical array in the VG corresponding to the storage system belonging to the server where the LVs are created from:
[root@se15:~]# lvcreate --name phaseH_storage_11_array0 phaseH_storage_11 -L 21.828T
[...]
[root@se15:~]# lvcreate --name phaseH_storage_11_array5 phaseH_storage_11 -L 21.828T
and
[root@se16:~]# lvcreate --name phaseH_storage_12_array0 phaseH_storage_12 -L 21.828T
[...]
[root@se16:~]# lvcreate --name phaseH_storage_12_array5 phaseH_storage_12 -L 21.828T
(information about the size to specify can be retrieved using pvdisplay)
- As defined in the previous step, on each machine there are 2 LVM Volume Groups, the one "belonging" to the machine and the one of the failover one:
# vgdisplay | grep 'phaseG_'
VG Name phaseG_storage_7
VG Name phaseG_storage_8
Then, for each VG we have several LV, some active (host that owns) and some inactive (failover host). The activation of the LV on each host is done via /etc/lvm/lvm.conf, especifically the line volume_list = [ "vg_root", "phaseG_storage_7" ]. Look below for more information: # lvdisplay
[...]
--- Logical volume ---
LV Path /dev/phaseG_storage_7/phaseG_storage_7_array0
LV Name phaseG_storage_7_array0
VG Name phaseG_storage_7
LV UUID F4pLAN-2ogh-MHie-cmVg-GFq0-ymEz-NtivUU
LV Write Access read/write
LV Creation host, time se11.lcg.cscs.ch, 2013-02-13 16:26:12 +0100
LV Status available
# open 1
LV Size 21.83 TiB
Current LE 5722080
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:14
[...]
--- Logical volume ---
LV Path /dev/phaseG_storage_8/phaseG_storage_8_array5
LV Name phaseG_storage_8_array5
VG Name phaseG_storage_8
LV UUID uZlUQt-43zL-r3DQ-t4rc-D03M-jOIi-q3jvou
LV Write Access read/write
LV Creation host, time se12.lcg.cscs.ch, 2013-02-13 16:27:42 +0100
LV Status NOT available
LV Size 21.83 TiB
Current LE 5722080
Segments 1
Allocation inherit
Read ahead sectors auto
This behaviour can be changed modifying the following lines on /etc/lvm/lvm.conf under the section devices {
obtain_device_list_from_udev = 1
[...]
volume_list = [ "vg_root", "phaseG_storage_7" ]
[...]
filter =[ "a|mapper|", "a|/dev/system_raid*|", "r|/dev/sd*|", "r|.*|" ]
- Overall this is a neat way of identifying what belongs where, but this extensive LVM modification has a problem: when installing a new kernel, during the rebuild of
vmlinuz and initramfs images, dracut includes by default the file /etc/lvm/lvm.conf which in turn, disallows the booting kernel to use any device on the path /dev/sd* (rule "r|/dev/sd*|"). This results on the system not knowing where vg_root is and, therefore, throwing a kernel panic. The solution is very simple:
- Modify
/etc/dracut.conf so it does not include any FC drivers or LVM configuration: # grep "lvmconf\|omit_drivers" /etc/dracut.conf
omit_drivers+="qla2xxx qla3xxx qla4xxx"
lvmconf="no"
- Rename the devices presented by the system's RAID controller so they do not match the remove
/dev/sd* rule on /etc/lvm/lvm.conf. This is done to avoid LVM not knowing where vg_root even after running /sbin/init. Obviously, an udev rule needs to be written here: # cat /etc/udev/rules.d/10-local.rules
# This is used to rename the block device sd?* of which parent has the attributes SUBSYSTEMS=="scsi", ATTRS{vendor}=="IBM", ATTRS{model}=="ServeRAID*" (system RAID)
# to a new name: system_raid_%k (%k makes it sdy/sda, the original name). So in the end, we would have /dev/system_raid_sda[1-16]
KERNEL=="sd?*", SUBSYSTEMS=="scsi", ATTRS{vendor}=="IBM", ATTRS{model}=="ServeRAID*",IMPORT{program}="/lib/udev/rename_device", NAME="system_raid_%k" As you can see, the devices presented to the OS by the system's RAID are renamed /dev/system_raid_sdXY. This allows the rule "a|/dev/system_raid*|", of /etc/lvm/lvm.conf to process the devices and, in turn, find the vg_root and the system /sbin/init # pvdisplay
Logging initialised at Thu Feb 21 10:35:32 2013
Set umask from 0022 to 0077
Scanning for physical volume names
--- Physical volume ---
PV Name /dev/system_raid_sdy2
VG Name vg_root
PV Size 278.27 GiB / not usable 19.00 MiB
Allocatable yes (but full)
PE Size 32.00 MiB
Total PE 8904
Free PE 0
Allocated PE 8904
PV UUID pYEgl2-sS1w-LvDF-mY7D-mXJE-szwr-FivgTT
[...]
- After completing the LVM configuration, filesystems can be created on LVs using
xfs:
[root@se15:~]# mkfs.xfs /dev/phaseH_storage_11/phaseH_storage_11_array0 -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f
[...]
[root@se15:~]# mkfs.xfs /dev/phaseH_storage_11/phaseH_storage_11_array5 -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f
[root@se16:~]# mkfs.xfs /dev/phaseH_storage_12/phaseH_storage_12_array0 -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f
[...]
[root@se16:~]# mkfs.xfs /dev/phaseH_storage_12/phaseH_storage_12_array5 -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f
- and eventually mount points can be created and
fstab edited to implement a manual failover:
[root@se15:~]# mkdir /data_phaseH_storage_11_array{0,1,2,3,4,5}
[root@se16:~]# mkdir /data_phaseH_storage_12_array{0,1,2,3,4,5}
[root@se15:~]# vim /etc/fstab
[...]
/dev/phaseH_storage_11/phaseH_storage_11_array0 /data_phaseH_storage_11_array0 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
[...]
/dev/phaseH_storage_11/phaseH_storage_11_array5 /data_phaseH_storage_11_array5 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
#/dev/phaseH_storage_12/phaseH_storage_12_array0 /data_phaseH_storage_12_array0 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
[...]
#/dev/phaseH_storage_12/phaseH_storage_12_array5 /data_phaseH_storage_12_array5 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
[root@se16:~]# vim /etc/fstab
[...]
#/dev/phaseH_storage_11/phaseH_storage_11_array0 /data_phaseH_storage_11_array0 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
[...]
#/dev/phaseH_storage_11/phaseH_storage_11_array5 /data_phaseH_storage_11_array5 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
/dev/phaseH_storage_12/phaseH_storage_12_array0 /data_phaseH_storage_12_array0 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
[...]
/dev/phaseH_storage_12/phaseH_storage_12_array5 /data_phaseH_storage_12_array5 xfs largeio,inode64,swalloc,noatime,nodiratime,logbufs=8,allocsize=131072k,nobarrier 0 1
please note how the first 6 lines are de-commented in se15 's fstab while the last 6 ones are commented, and vice-versa in se16 's fstab since Stoarge11 belongs to se15 and Storage12 belongs to se16. Now a mount -a should mount all the LVs on the respective mount points and a df should show the available space. At this point the pools' configuration can be performed.
Install notes for se[17-18]
Because these two nodes share only one pair of controllers (and
two enclosures), the configuration is slightly different in the sense that there are two VG, with PV and LV assigned as follows:
- PV: all on both machines (
/dev/mapper/phaseH_storage_r6_1_array[0-11] ). # for i in $(seq 0 11); do [[ -e /dev/mapper/phaseH_storage_r6_1_array${i} ]] && echo pvcreate /dev/mapper/phaseH_storage_r6_1_array${i}; done
- Volume Groups:
- VolumeGroup on se17
phaseH_storage_r6_1_17 (array 0-5) [root@se17:~]# vgcreate phaseH_storage_r6_1_17 /dev/mapper/phaseH_storage_r6_1_array0 /dev/mapper/phaseH_storage_r6_1_array1 /dev/mapper/phaseH_storage_r6_1_array2 /dev/mapper/phaseH_storage_r6_1_array3 /dev/mapper/phaseH_storage_r6_1_array4 /dev/mapper/phaseH_storage_r6_1_array5
- VolumeGroup on se18
phaseH_storage_r6_1_18 (array 6-11) [root@se18:~]# vgcreate phaseH_storage_r6_1_18 //dev/mapper/phaseH_storage_r6_1_array6 /dev/mapper/phaseH_storage_r6_1_array7 /dev/mapper/phaseH_storage_r6_1_array8 /dev/mapper/phaseH_storage_r6_1_array9 /dev/mapper/phaseH_storage_r6_1_array10 /dev/mapper/phaseH_storage_r6_1_array11
- Logical Volumes:
[root@se17:~]# for i in $(seq 0 5); do [[ -e /dev/mapper/phaseH_storage_r6_1_array${i} ]] && lvcreate --name phaseH_storage_r6_1_17_array${i} --extents 100%PVS phaseH_storage_r6_1_17 /dev/mapper/phaseH_storage_r6_1_array${i}; done
[root@se18:~]# for i in $(seq 6 11); do [[ -e /dev/mapper/phaseH_storage_r6_1_array${i} ]] && lvcreate --name phaseH_storage_r6_1_18_array${i} --extents 100%PVS phaseH_storage_r6_1_18 /dev/mapper/phaseH_storage_r6_1_array${i}; done
- Filesystems:
[root@se17:~]# for i in $(ls /dev/mapper/ |grep phaseH_storage_r6_1_17|awk -F'-' '{print $2}'); do mkfs.xfs /dev/phaseH_storage_r6_1_17/${i} -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f; mapperdevice=$(echo ${i} | sed 's/_17//g'); echo "/dev/phaseH_storage_r6_1_17/${i} /${mapperdevice} xfs defaults 0 0" >> /etc/fstab ; mkdir -p /${mapperdevice};done
[root@se18:~]# for i in $(ls /dev/mapper/ |grep phaseH_storage_r6_1_18|awk -F'-' '{print $2}'); do mkfs.xfs /dev/phaseH_storage_r6_1_18/${i} -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f; mapperdevice=$(echo ${i} | sed 's/_18//g'); echo "/dev/phaseH_storage_r6_1_18/${i} /${mapperdevice} xfs defaults 0 0" >> /etc/fstab ; mkdir -p /${mapperdevice};done
Install notes for se[19-22]
These nodes share only one set of controllers (and
3 enclosures) per pair
- se19/20: PV all / VG
phaseJ_storage_r2_1_se19 and phaseJ_storage_r2_1_se20 / LV odd PVs active (1 3 5 7 9 11 13 15 17) on se19 and even PVs active (0 2 4 6 8 10 12 14 16) on se20. Space available is 270TiB per machine after RAID, partitioning and formatting (XFS). Total 540TiB per pair.
- se21/22: PV all / VG
phaseJ_storage_r1_1_se21 and phaseJ_storage_r1_1_se22 / LV odd PVs active (1 3 5 7 9 11 13 15 17) on se21 and even PVs active (0 2 4 6 8 10 12 14 16) on se22. Space available is 270TiB per machine after RAID, partitioning and formatting (XFS). Total 540TiB per pair.
This is how the LVM and filesystem are distributed and created:
- Physical Volumes are shared across pairs (
/dev/mapper/phase*array* ): Run this on all 4 servers: # for i in $(ls /dev/mapper/phase*array* |grep -v -E 'p1|p2|p3'); do [[ -e $i ]] && pvcreate $i; done
- Volume Groups are shared across pairs:
- VolumeGroup on se19
phaseJ_storage_r2_1_se19 # vgcreate phaseJ_storage_r2_1_se19 /dev/mapper/phaseJ_storage_r2_1_array17 /dev/mapper/phaseJ_storage_r2_1_array15 /dev/mapper/phaseJ_storage_r2_1_array13 /dev/mapper/phaseJ_storage_r2_1_array11 /dev/mapper/phaseJ_storage_r2_1_array9 /dev/mapper/phaseJ_storage_r2_1_array7 /dev/mapper/phaseJ_storage_r2_1_array5 /dev/mapper/phaseJ_storage_r2_1_array3 /dev/mapper/phaseJ_storage_r2_1_array1
- VolumeGroup on se20
phaseJ_storage_r2_1_se20 # vgcreate phaseJ_storage_r2_1_se20 /dev/mapper/phaseJ_storage_r2_1_array16 /dev/mapper/phaseJ_storage_r2_1_array14 /dev/mapper/phaseJ_storage_r2_1_array12 /dev/mapper/phaseJ_storage_r2_1_array10 /dev/mapper/phaseJ_storage_r2_1_array8 /dev/mapper/phaseJ_storage_r2_1_array6 /dev/mapper/phaseJ_storage_r2_1_array4 /dev/mapper/phaseJ_storage_r2_1_array2 /dev/mapper/phaseJ_storage_r2_1_array0
* VolumeGroup on se21 phaseJ_storage_r1_1_se21 # vgcreate phaseJ_storage_r1_1_se21 /dev/mapper/phaseJ_storage_r1_1_array17 /dev/mapper/phaseJ_storage_r1_1_array15 /dev/mapper/phaseJ_storage_r1_1_array13 /dev/mapper/phaseJ_storage_r1_1_array11 /dev/mapper/phaseJ_storage_r1_1_array9 /dev/mapper/phaseJ_storage_r1_1_array7 /dev/mapper/phaseJ_storage_r1_1_array5 /dev/mapper/phaseJ_storage_r1_1_array3 /dev/mapper/phaseJ_storage_r1_1_array1
* VolumeGroup on se22 phaseJ_storage_r1_1_se22 # vgcreate phaseJ_storage_r1_1_se22 /dev/mapper/phaseJ_storage_r1_1_array16 /dev/mapper/phaseJ_storage_r1_1_array14 /dev/mapper/phaseJ_storage_r1_1_array12 /dev/mapper/phaseJ_storage_r1_1_array10 /dev/mapper/phaseJ_storage_r1_1_array8 /dev/mapper/phaseJ_storage_r1_1_array6 /dev/mapper/phaseJ_storage_r1_1_array4 /dev/mapper/phaseJ_storage_r1_1_array2 /dev/mapper/phaseJ_storage_r1_1_array0
- Logical Volumes are shared across pairs, but only active on one of the two systems of the pair at the same time. For this to work make sure the entry
volume_list in lvm.conf has the correct version of [ "vg_root","phaseJ_storage_r2_1_se19" ]. Run this on all 4 servers: # for id in $(pvdisplay 2>/dev/null |grep phaseJ_storage_r2_1_$(hostname -s) -B 1 |grep 'PV Name' | awk {'print $3}'); do lvcreate --name $(basename $id) --extents 100%PVS phaseJ_storage_r2_1_$(hostname -s) $id; done
- Filesystems. Run the following on all 4 servers:
# for device in $(lvdisplay 2>/dev/null |grep $(hostname -s) |grep 'LV Path' | awk '{print $3}'); do mkfs.xfs $device -b size=4096 -d su=128k,sw=10 -l version=2,su=128k -f ;echo "$device /data_$(basename $device) xfs defaults 0 0" >> /etc/fstab; mkdir /data_$(basename $device); done
Some of these solutions can be checked in
http://trac.dcache.org/wiki/TroubleShooting
- If you get this message when trying to send files to the SE
with error Best pool too high : Infinity, you need to change the gap in each pool: set gap 10m
The reason why this happens is that the default gap is set by default to 4G, and if you are using pools with less free space than that (very likely in preproduction), transfers will never reach the pools. More info here (release 1.9.5): http://www.dcache.org/manuals/Book-1.9.5/config/cf-pm-cm.shtml#cf-pm-cm-space = set gap /size[] # unit = k|m|g=
- se[-9-14] FC connections:
-
-
-
-

HP FC connections
The physical layout of the FC ports on the HP machines goes from left to right, example image below. If in doubt use 'systool -c fc_host -v' to verify.

The connections are made as follows;
In future expansion additional controllers can be connected to port 1 of the cards on the SE machines, connecting to both controllers on ports 0 and 2 in the same fashion.
FC Host | Controller
----------|------------
C0P0 | C0P0
C1P0 | C1P2
FC Host | Controller
----------|------------
C0P0 | C1P0
C1P0 | C0P2
DBs backups in /var/lib/pgsql/
Show... Hide
Dec 02 17:33 [root@storage02:store]# dcache database ls
DOMAIN CELL DATABASE HOST USER MIN- MAX-CONNS MANAGEABLE AUTO
namespaceDomain PnfsManager chimera localhost postgres 30 90 Yes Yes
namespaceDomain cleaner chimera localhost postgres No No
nfs-storage02Domain NFSv41-storage02 chimera localhost postgres No No
TOTAL 30 90
Dec 02 17:33 [root@storage02:store]# exit
logout
Connection to storage02 closed.
Dec 02 17:34 [fmartinelli@pub:~]$ ssh root@storage01 dcache database ls
DOMAIN CELL DATABASE HOST USER MIN- MAX-CONNS MANAGEABLE AUTO
utilityDomain PinManager dcache localhost srmdcache Yes Yes
srm-storage01Domain SRM-storage01 dcache localhost srmdcache No Yes
srm-storage01Domain SrmSpaceManager dcache localhost srmdcache No Yes
srm-storage01Domain RemoteTransferManager dcache localhost srmdcache No Yes
TOTAL 0 0
Dec 2 05:16:50 storage02 backup[31936]: backup 3 starting at Mon Dec 2 05:16:50 CET 2013
Dec 2 05:16:50 storage02 backup[31936]: Archival destination: archive=lcgarc@ela.cscs.ch:/store/system/Phoenix/
Dec 2 05:16:50 storage02 backup[31936]: Base directory: basedir=/opt/backup
Dec 2 05:16:50 storage02 backup[31936]: Log files directory: logdir=/opt/backup/log
Dec 2 05:16:50 storage02 backup[31936]: Incremental backup state directory: statedir=/opt/backup/state
Dec 2 05:16:50 storage02 backup[31936]: Tar command: tar=/bin/tar
Dec 2 05:16:50 storage02 backup[31936]: Additional tar options: tar_options=
Dec 2 05:16:50 storage02 backup[31936]: SSH command: ssh=/usr/bin/ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no
Dec 2 05:16:50 storage02 backup[31936]: SSH identity key: /opt/backup/etc/id_rsa_backup
Dec 2 05:16:50 storage02 backup[31936]: Creating backup directory '/store/system/Phoenix//2013/12/02' ...
Dec 2 05:16:50 storage02 backup[31936]: Warning: Permanently added 'ela.cscs.ch,148.187.1.6' (RSA) to the list of known hosts.#015
Dec 2 05:16:51 storage02 backup[31936]: Would backup 'storage02:/var/lib/pgsql/dumpall-c_complete.sql' to remote file 'storage02_var_lib_pgsql_dumpall-c_complete.sql.tar'.
Dec 2 05:16:51 storage02 backup[31936]: Running a full backup (requested by '-f' command-line option).
Dec 2 05:16:51 storage02 backup[31936]: Warning: Permanently added 'ela.cscs.ch,148.187.1.6' (RSA) to the list of known hosts.#015
Dec 2 05:17:13 storage02 backup[31936]: Warning: Permanently added 'ela.cscs.ch,148.187.1.6' (RSA) to the list of known hosts.#015
Dec 2 05:17:38 storage02 backup[31936]: Warning: Permanently added 'ela.cscs.ch,148.187.1.6' (RSA) to the list of known hosts.#015
Dec 2 05:17:55 storage02 backup[31936]: Warning: Permanently added 'ela.cscs.ch,148.187.1.6' (RSA) to the list of known hosts.#015
Dec 2 05:18:19 storage02 backup[31936]: Warning: Permanently added 'ela.cscs.ch,148.187.1.6' (RSA) to the list of known hosts.#015
Dec 2 05:18:45 storage02 backup[31936]: Backup of 'storage02:/var/lib/pgsql/dumpall-c_complete.sql' finished (with exitcode 0)
Dec 2 05:18:45 storage02 backup[31936]: backup done at Mon Dec 2 05:18:45 CET 2013
Materialized views
The storage02 machine has Fabio's materialized views installed (
https://bitbucket.org/fabio79ch/v_pnfs/wiki/Home). This provides a very usefull table of pnfsid's, paths, access times and creation times.
Refresh the view
The view is generated from a query so the data contained within it drifts as time goes on. The view can be refreshed with the following, this took around 20 minutes when the system was under minimal load. On a a test system this took 45 minutes.
su - postgres
psql
psql> \c chimera
psql> REFRESH MATERIALIZED VIEW v_pnfs;
Space monitor
- Every night there is a script that runs (
storage02:/etc/cron.daily/run_space_monitor2.sh ) and generates a few pages on Ganglia that show the internal space utilisation per folder for each of the three VOs:
- ATLAS
- CMS
- LHCb
- Please note that this script *refreshes the materialised views( as required!
Issues
Can't remove file from NFS
This was due to root squashing in the NFS export options of storage02. I was able to change the options in /etc/exports and restart in NFS domain in production on the fly without issue. Would not recommend doing this outside of a downtime unless you really need to.
lcg-getturl returns file:/pnfs/.... on WN
This was due to the nfs4.1 service offering files.
Note the "loginBroker=srm-LoginBroker" does not mean this is broker used by the SRM but the login broker the SRM itself registers with.
#dCache CLI
cd LoginBroker
disbale NFSv41-storage02@nfs-storage02Domain
#To fix permanently change the login broker
vim /etc/dcache/layouts/storage01.conf
[nfs-${host.name}Domain]
[nfs-${host.name}Domain/nfsv41]
loginBroker=srm-LoginBroker
Before and after
lcg-getturls -p file,gsiftp srm://storage01.lcg.cscs.ch/pnfs/lcg.cscs.ch/dteam/test1244
file:/pnfs/lcg.cscs.ch/dteam/test1244
lcg-getturls -p file,gsiftp srm://storage01.lcg.cscs.ch/pnfs/lcg.cscs.ch/dteam/test1244
gsiftp://se10.lcg.cscs.ch:2811/pnfs/lcg.cscs.ch/dteam/test1244
This caused a temporary issue where some CMS failed as the above change removed the following information published from the BDII. As such this change took over 12 hours to propagate to the top BDII.
#The following entries were removed the published information
NFSv41-storage02@nfs-storage02Domain, storage01.lcg.cscs.ch, CSCS-LCG2, local, grid
dn: GlueSEAccessProtocolLocalID=NFSv41-storage02@nfs-storage02Domain,GlueSEUni
queID=storage01.lcg.cscs.ch,Mds-Vo-name=CSCS-LCG2,Mds-Vo-name=local,o=grid
GlueSEAccessProtocolLocalID: NFSv41-storage02@nfs-storage02Domain
: file transfer
objectClass: GlueSETop
objectClass: GlueSEAccessProtocol
objectClass: GlueKey
objectClass: GlueSchemaVersion
GlueSEAccessProtocolMaxStreams: 5
GlueSchemaVersionMinor: 3
GlueSEAccessProtocolVersion: file
GlueSEAccessProtocolEndpoint: file://storage02.lcg.cscs.ch:2049
GlueChunkKey: GlueSEUniqueID=storage01.lcg.cscs.ch
GlueSchemaVersionMajor: 1
GlueSEAccessProtocolType: file
Unable to write to NFS mount
If you get IO errors when attempting to write to the NFS mount of /pnfs or doing transfers and see the following in the logs check the pool you are writing to isn't low on free space. Check the pool logs for the "Too high infinity crap blah blah blah" message.
May 12 09:34:32 storage02 kernel: NFS: v4 server returned a bad sequence-id error on an unconfirmed sequence ffff880037059a68!
May 12 09:34:32 storage02 kernel: NFS: v4 server storage02 returned a bad sequence-id error!
Changing movers on the fly
The settings can be for the number of movers can be changed on the fly via the dCache ssh interface. This is usefull if the setup file was not added to the root of the pool in the initial install for example.
# cd to the pool you wish to edit
cd data_phaseG_storage_7_array0_cms
# View current settings
mover queue ls -l
regular 0 100 0
p2p 0 10 0
wan 0 2 0
# Change the settings
mover set max active 10 -queue=wan
save
# Confirm change
mover queue ls -l
regular 0 100 0
p2p 0 10 0
wan 0 10 0



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}