CHIPP-CSCS Face to Face Meeting on 2018-01-25
- Date and time: Thursday 25th of January at 10:10 (time should be fine for the 7:32 train from Zurich / 8:18 from Arth-Goldau)
- Place: Lugano (CSCS)
- External link / EVO: Win/Mac: https://vcmeeting.ethz.ch/
 (Room: 6708238) | Linux(vidyo): sip:6708238@vc.ethz.ch | Phone gate: +41 43 244 8930 (ext 6708238 #)
(Room: 6708238) | Linux(vidyo): sip:6708238@vc.ethz.ch | Phone gate: +41 43 244 8930 (ext 6708238 #)
Agenda
- 10:10 - Welcome, coffee and agenda
- 10:30 - Update from the Computing Board (15' - Christoph)
- 10:45 - VO Status report (~last 6 months + changes since last F2F, for both Phoenix and CRAY)
- LHCb (20' - Roland)
- ATLAS (20' - Gianfranco)
- CMS (20' - Thomas)
- 11:45 - Tier-2 status, plans & pledges
- CSCS (45' - Various people, for both Phoenix and CRAY)
- UNIBE-LHEP (30' - Gianfranco)
- 13:00 - Lunch
- 14:15 - Tier-3 status and plans
- PSI (15' - Nina)
- UNIBE-ID (15' - Gianfranco)
- UNIGE (10' - Gianfranco)
- 15:00 - Coffee break
- 15:15 - NGI_CH (20' - Gianfranco)
- 15:35 - Discussion / fix pledges (55')
- 16:30 - End of meeting
Attendants
- CSCS:
- CMS:
- ATLAS: Gianfranco
- LHCb: Roland
Minutes
- LHCb
- Some tickets get never resolved because the problem goes away
- ACTION: Roland shall try to follow up next time it happens
- ACTION: CSCS should plug in the Nagios tests from LHCb to get the input from the SAM tests (to keep the site green, otherwise LHCb does not care much)
- ATLAS
- ACTION: CSCS should check if the hammercloud queues go offline notification email arrives.
- End-of-November is where the issues focus (ATLAS could not follow up)
- arc04 looks red since end-of-November. Nagios checks (if imported into our nagios) should have shown it... but it was not reported either (it only affects A/R metrics)
- ACTION: Fair-share needs to be looked at (some details needed in the next meetings)
- ACTION: We should make sure we do the monthly operatoins meetings, even if we have F2F meetings
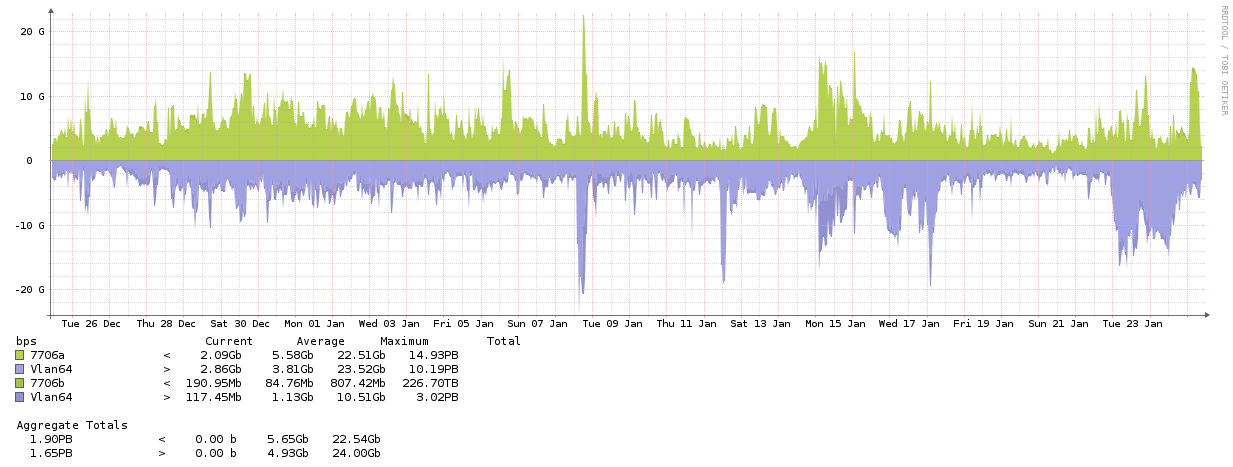
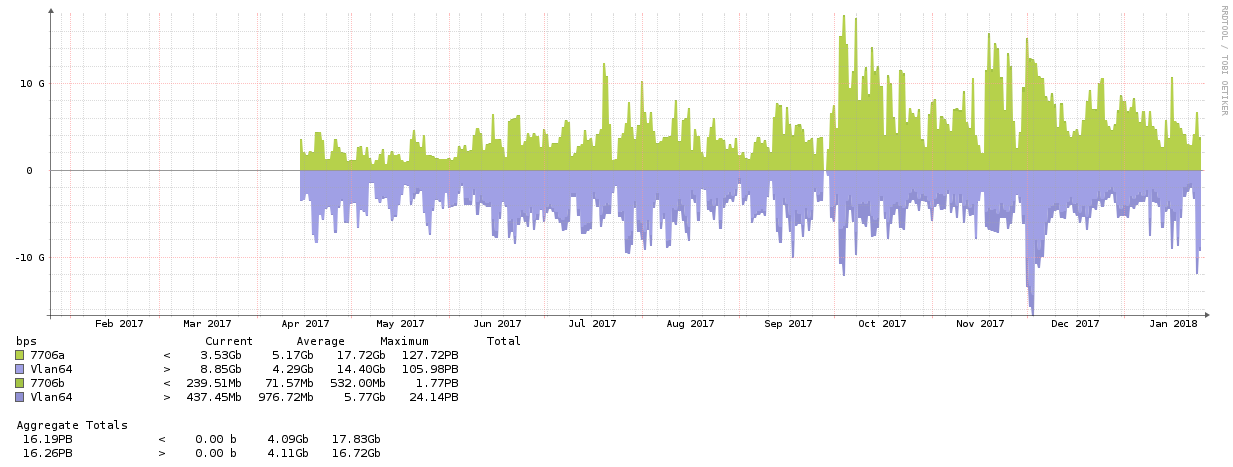
- There are fluctuations in performance, most probably GPFS around December. This also shows clear in the ATLAS IO workloads.
- ACTION: CSCS should follow up. ATLAS can try to check different IO mechanisms (direct-IO and/or usage of local disks)
- CMS
- Pledge delivery looks very bad: part of it is coming from lack of information on the CMS side, but there is also a part (which shows in the CSCS charts) is related to CSCS compute: it looks like either the queue pressure is not sufficient or the fairshare might be wong.
- UNIBE
- Hardening the monitoring has paid back with lower failure rates
Other Action items
- all VO representatives shall evaluate the needs of the VOs for the next 4 years in terms of CPU, DISK, TAPE, ratios
- also whether the increase over the years should be continuous or not
- CSCS shall make a statement on what part of phoenix and on what timescale will be available to CHIPP for re-usage.
- Bern hopes for 50% of the PHOENIX hardware in 2019.
- Other VOs shall make a statement what they want from HW.
- clarify pledges numbers; and prepare 2019 pledges to be entered in Sep. 2018 including LHConCRAY growth of 27% (use 25% ?) CPU and 15% storage.
- Objection raised by ATLAS to changing the CPU shares from 40:40:20 to 37.5:37.5:25 without a clear mandate by the CHIPP CB. ATLAS will consider 40:40:20 effective share (despite wrong pledges in REBUS) until a decision to change this will be taken and announced with a protocol.
- A CPU and disk growth plan by ATLAS (part of the decision to move to the Cray platform) has been presented. This is based on the agreed growth rates of 27% and 15% storage. The ATLAS number show slightly different ratios for CPU and disk that should be clarified before any change to the batch shares are implemented.
- The other VOs have been asked to pur forward similar plans.
Attachments
- ATLAS-report-20180125.pdf: ATLAS VO report
- UNIBE-LHEP-20180125.pdf: UNIBE-LHEP Tier2 report
- UNIGE-DPNC-20180125.pdf: UNIGE-DPNC Tier3 report
- chipp-cscs-f2f-20180125.pdf: chipp-cscs-f2f-20180125.pdf


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
0125_F2F_v2.pdf | r1 | manage | 1013.6 K | 2018-01-25 - 09:30 | ThomasKlijnsma | CMS VO Report |
| |
20180125_F2F_CSCS.pptx | r1 | manage | 3730.7 K | 2018-01-25 - 09:00 | PabloFernandez | |
| |
ATLAS-report-20180125.pdf | r1 | manage | 1905.4 K | 2018-01-25 - 08:20 | GianfrancoSciacca | ATLAS VO report |
| |
LHCb_CHIPP_Lugano_Jan2018.pdf | r1 | manage | 862.8 K | 2018-01-25 - 10:01 | RolandBernet | |
| |
Network_-_last-month.png | r1 | manage | 111.1 K | 2018-01-25 - 09:03 | DinoConciatore | Network usage |
| |
Network_-_last-week.png | r1 | manage | 123.3 K | 2018-01-25 - 09:03 | DinoConciatore | Network usage |
| |
Network_-_last-year.png | r1 | manage | 87.2 K | 2018-01-25 - 09:03 | DinoConciatore | Network usage |
| |
UNIBE-LHEP-20180125.pdf | r1 | manage | 1269.2 K | 2018-01-25 - 09:42 | GianfrancoSciacca | UNIBE-LHEP Tier2 report |
| |
UNIGE-DPNC-20180125.pdf | r1 | manage | 98.0 K | 2018-01-25 - 09:43 | GianfrancoSciacca | UNIGE-DPNC Tier3 report |
| |
chipp-cscs-f2f-20180125.pdf | r1 | manage | 518.8 K | 2018-01-25 - 10:13 | DerekFeichtinger |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This topic: LCGTier2 > WebHome > MeetingsBoard > MeetingCHIPPCSCSFaceToFace20180125
Topic revision: r12 - 2018-02-20 - GianfrancoSciacca
Ideas, requests, problems regarding TWiki? Send feedback