Swiss Grid Operations Meeting on 2013-07-04
- Date and time: First Thursday of the month, at 14:00
- Place: Vidyo (room: Swiss_Grid_Operations_Meeting, extension: 9227296)
- External link: http://vidyoportal.cern.ch/flex.html?roomdirect.html&key=Nrq24qRR4V1u

- Phone gate: From Switzerland: 0225330322 (portal) + 9227296 (extension) + # (pound sign)
- IRC chat: irc:gridchat.cscs.ch:994#lcg (ask pw via email)
Agenda
Status- CSCS (reports Miguel):
- All workernodes updated to SL6/ UMD 2
- No longer using fakeraid, one disk for OS one for CVMFS
- Problems with gridftp transfers from certain sites, cause was our IB/Ethernet bridge not negotiating MTUs correctly
- atlasvobox decommissioned
- cmsvobox was found hung and would no longer boot under Xen. Migrated to KVM and brought machine back up.
- lrms02 moved to KVM, no more Xen machines
- Cream machines updated to latest release
- PSI (reports Fabio/Daniel):
- Generally quiet (holiday period); but some new users that need support and/or additional software packages installed
- Cluster was "offline" for about 2 hours on Thursday June 26th (SWITCHlan network issue; ticket that left PSI without any network connection)
- Virtual infrastructure at PSI seems to have stabilized (at least we did not see an other problems with our crucial dCache Chimera VM)
- Usual fileserver/HDD problems continue; luckily everything so far was recoverable by reboots only (i.e. no data migrations necessary)
- Our Chimera DB constantly has >250 connections open (out of 300 we have configured as a maximum)
- The numbers seems to be almost constant; independent of actual usage
- Maybe it's just trying to improve performance as best as possible within the defined limit or maybe there is something wrong with our configuration/installation
- Situation not yet exactly understood (however, as it constantly stays <~90% this is not a high-priority issue for us)
- Constantly "fighting" over-usage and clean-up laziness by certain users; our SE is now ~95% full
- Started doing some tests with OpenMPI (so far single node only)
- UNIBE (reports Gianfranco):
- Older cluster running stable, will move it to SLC6 after summer and run it until it dies.
- Newer cluster running stable at full load, with I/O light tasks (had problems with eth0 lockup on at least 3 Lustre OSS nodes)
- Now ready to move Lustre to the ib0 network (negotiating downtime with Andrej, very likely early next week)
- Then commission for I/O heavy MC tasks (Reco) and eventually Analysis
- Ready to move to Lustre 2.1.6 on servers (this supports the latest kernel 2.6.32-358.11.1.el6.x86_64). Not clear if will do this now
- Network drop last week: we had a long-ish interruption, but were not affected really, jobs resumed happily afterwards
- Issue: we are not publishing to APEL the usage records from the newer cluster.
- Needs intervention on the Swiss SGAS side (who is maintaining this now, I guess it is still under SWITCH)
- Jura publisher of latest version of ARC not ptoduction ready yet (but we can piggy back on efforts in DE and UK who are moving to ARC)
- Not clear whether we are advertising our cluster correctly on the site-bdii (e.g. "GlueHostProcessorOtherDescription")
- UNIBE-ID cluster operating smoothly and excellent synergy with admins. 600 slots for ATLAS, might pledge resources from there too
- UNIGE (reports Szymon):
- Xxx
- UZH (reports Sergio):
- Xxx
- Switch (reports Alessandro):
- Xxx
- CMS
- CMS site configuration was migrated to git Wednesday June 26th. A trivial error in the migration script lead to a lot of killed jobs everywhere within a few hours that day; so if you saw something on that day for CMS this was most probably not a site issue.
- From the CMS side the main issue of the last month really was the network problems that started mid-June (see e.g. on this transfer quality plot that 3 links to T1 got bad around June 13th)
- After some painstaking investigation we found out it was an MTU/MSS issue that is now temporarily solved by setting
ifconfig ib0 mtu 2044on all dCache head nodes (I guess more details can/will be discussed in the CSCS part)- Do we also need to apply this fix on WNs? Otherwise stage-out from the WNs to e.g. FNAL could also fail
- Transfers have resumed Monday evening and from our side it looks ok now
- Did something change in the Scheduled Downtime workflow from our side? For about two months now CMS seems to be unable to detect those downtimes correctly; also, we do not receive the automated start/finish e-mails from GOCDB anymore.
- Successfully registered the CSCS queues as SL6 queues within the CMS submitting infrastructure - waiting for first results
-
cmsvoboxwas down over the last weekend and was then migrated to a KVM machine; will try to migrate the last service that runs there within the next days
- ATLAS
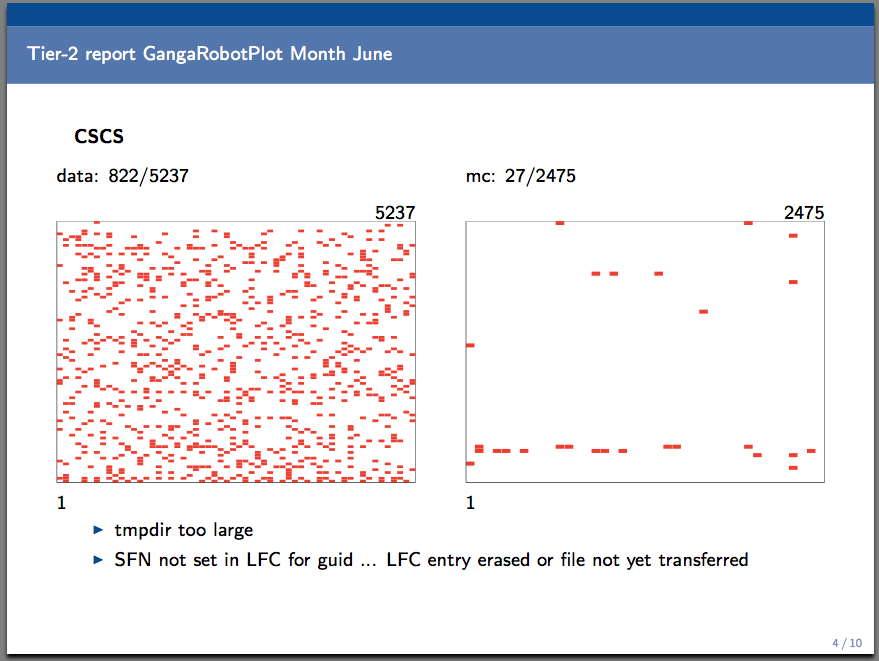
- HammerCloud random failures increasing in frequency (see attachment). Many autoexclusions/withelistings for the ANALY queue
- Hard to hunt down the cause, error misleading (related to the size of the workdir). Real cause not understood yet (no site issue)
- FAX and PerfSonar deployment still open
- ATLAS DE cloud face to face at CSCS: date fixed for 30 Sep- 01 Oct 2013 (official announcement will follow)
- HammerCloud random failures increasing in frequency (see attachment). Many autoexclusions/withelistings for the ANALY queue
- Topic3
Attendants
- CSCS:
- CMS:
- ATLAS:
- LHCb:
- EGI:
Action items
- Item1


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
ATLAS_HC-CSCS-June.png | r1 | manage | 59.8 K | 2013-07-04 - 09:30 | GianfrancoSciacca |
{kind=link}
{kind=link}
This topic: LCGTier2 > WebHome > MeetingsBoard > MeetingSwissGridOperations20130704
Topic revision: r5 - 2013-07-04 - GianfrancoSciacca
Ideas, requests, problems regarding TWiki? Send feedback