Swiss Grid Operations Meeting on 2016-05-12 at 14:00
- Place: Vidyo (room: Swiss_Grid_Operations_Meeting, extension: 109305236)
- External link: http://vidyoportal.cern.ch/flex.html?roomdirect.html&key=gDf6l4RlIAGN

- Phone gate: From Switzerland: 0227671400 (portal) + 109305236 (extension) + # (pound sign)
- IRC chat: irc:gridchat.cscs.ch:994#lcg (ask pw via email)
- Switch Vidyo SIP IP: 137.138.248.204
Site status
CSCS
SYSTEM- IB eth bridges replaced
- A few IB QDR switches replaced with FDR switches
- Compute nodes re-installed
- CSCS Central puppet
- CSCS LDAP for users
- CSCS NFS for home
- ARC CE fresh installed with the following queues:
- arc01 64nodes (sandy bridge nodes, 64GB ram, 32 cores)
- arc02 48 nodes (ivy bridge nodes, 128GB ram, 40 cores)
- arc03 40 nodes (haswell nodes, 128GB ram, 48 cores) soon updated to v4
- CREAM01/02/03: reviewing accounting before final shutdown
- All Virtual machines are running on CSCS central VMware
- CMS re-installation to be planned with Puppet base installation (Firewall, Users, Grid Certificates, ..)
- Current allocation over 90%
- Allocation problems on the old 64GB RAM nodes (arc01 queue)
- GPFS
- Few weeks ago we reached 310M of used inodes on the scratch fileset
- servers high load -> slow cleaning policy -> job problems
- filesystem stayed online
Consequence
-
- per user inode quota (50M)
- inode usage alerts
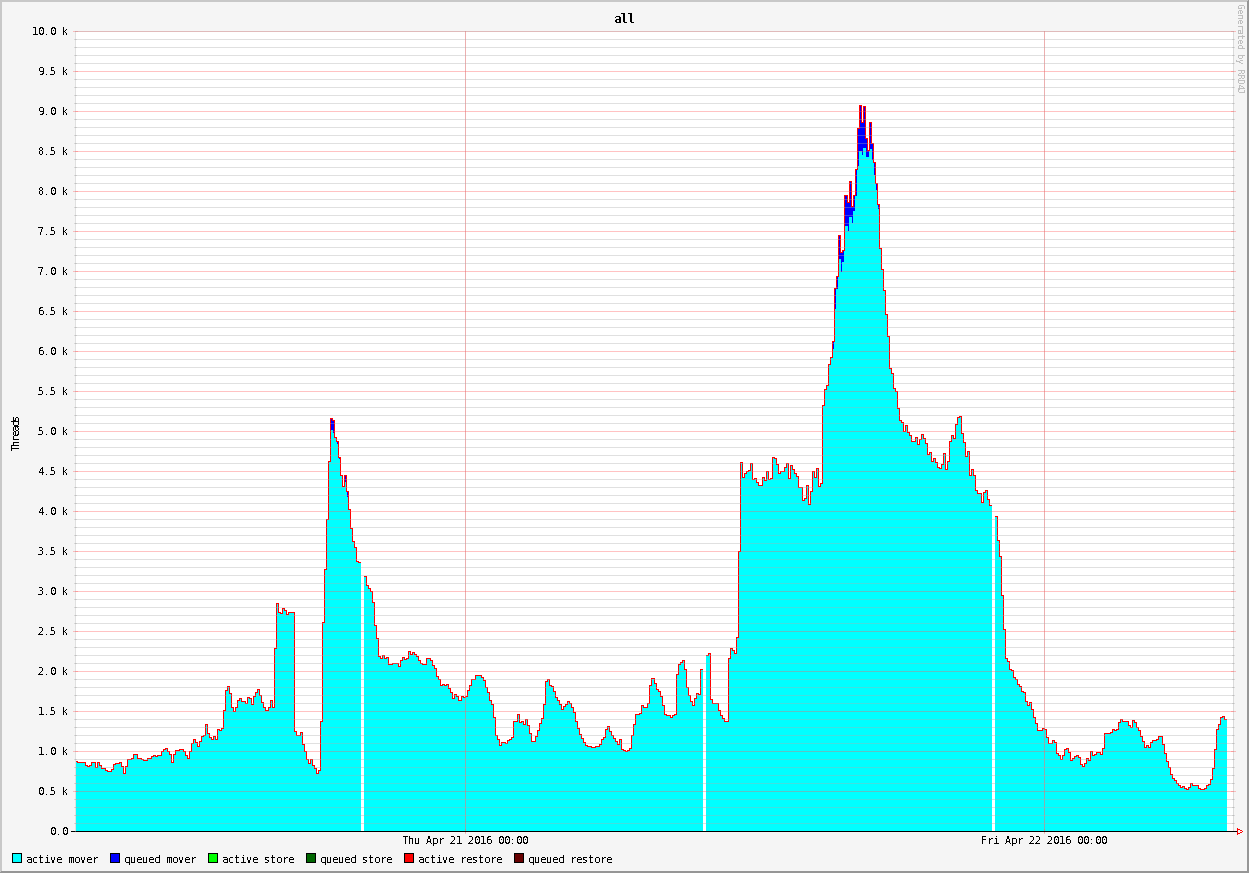
- dCache
- 9K+ active connections (record?)
- 12+GBit internet bandwith measured on the network (2x 6+Gbit)
- Real limit was about 2x8Gbit
- New limit is about 80Gbit with the new gateways

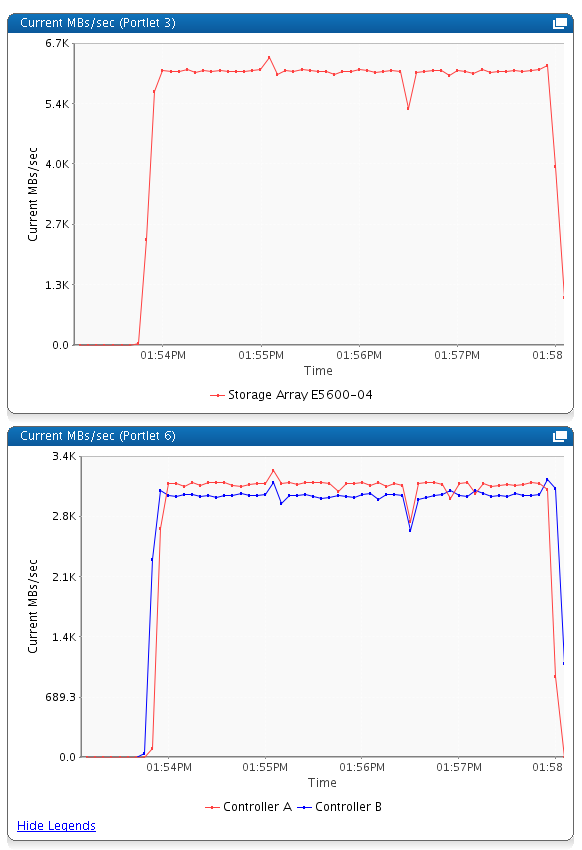
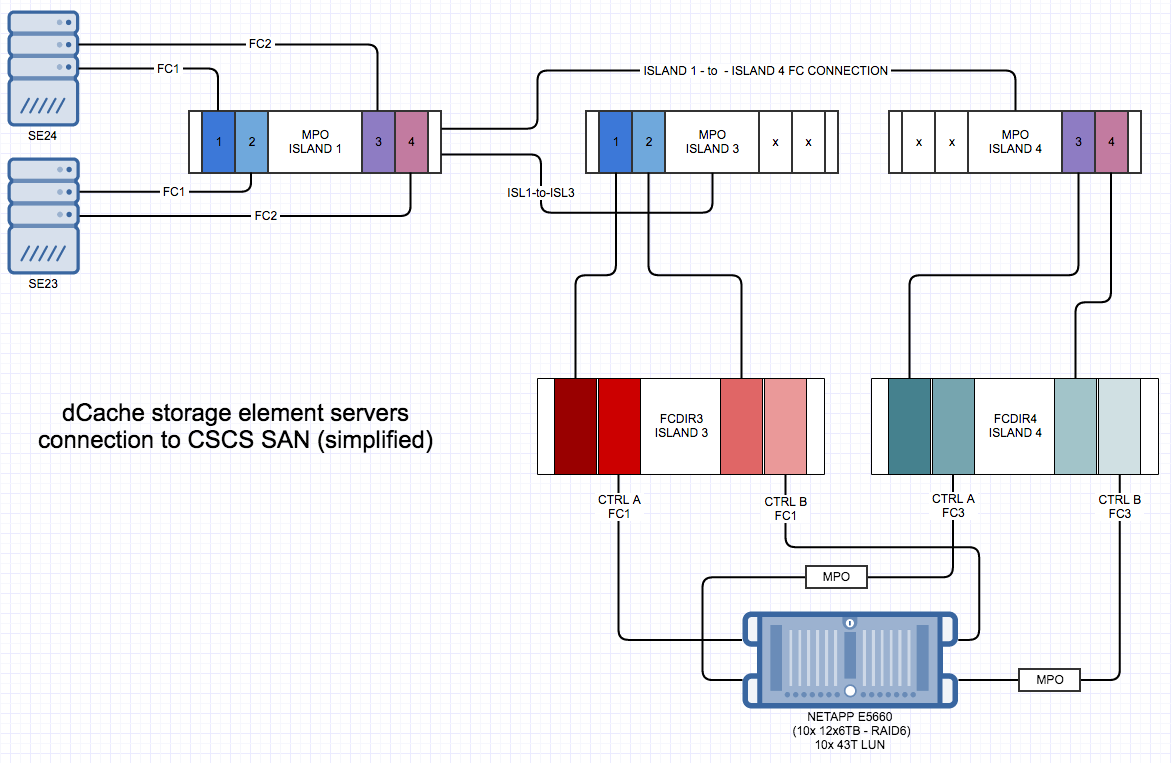
Some technical details and numbers of the new storage that will be available in the next days (1PB)
- NETAPP (0.5PB)
2xController / 4xFC16 Links / 10xLUNs / 12x6TB drives per LUN (RAID6)
Architecture
Performances (6x dd from 2 servers each on a different LUN, 3x controller)
- DDN SFA12K (0.5PB)
2x Controller / 4x Storage Processors / 4x FC16 Links (1xStorage Processor) / 24LUNs / 10x3TB drives per LUN (RAID6)
Architecture -> same CSCS integration
Performances will follow asap
PSI
- T3 upgraded to 10Gbs
- The local Net team deployed a CISCO Extender, 32 ports 10Gbs CAT6, 8 uplinks 10Gbs in Fibre ; so far 4/8 uplinks cabled
- The 32 ports can be organized as LACP groups ; we made 5 groups with 2 ports inside ( Tot. 10 ports cabled ) ; both the dCache Storage servers and the ZFS/NFSv4 NAS are connected to these LACP groups
- Other 9 ports are used for the latest 10Gbs WNs ( ~500 CPUs core )
- Generally speaking, it was a nice 1Gbs to 10Gbs transition without unexpected troubles
- dCache upgraded from 2.13 to 2.15
- Configuration files as in 2.13 worked also in 2.15, nice
- But the Chimera Tables changed ; there is a new field inumber that's used as a key here and there in respect of
ipnfsidage ( that's still in the tables though ) - The Chimera Table change means that both chimera-dump and my materialized view v_pnfs don't work right now
- I won't update chimera-dump while I'm updating v_pnfs to be 2.15 compatible ; CSCS will have my same issues on its own dCache roadmap
- Configuration files as in 2.13 worked also in 2.15
- Need to distinguish between NFSv4 interactive traffic ( users ) and batch system traffic ( jobs )
- Accounting numbers (from scheduler) from last month
UNIBE-LHEP
Operations- stable, no incidents to report
- HC online ~90% (last month). Still room for improvement, btu not too big impact since interruptions are not long enough to cause the site to drain. UNIBE-ID >96%
- 52% of ATLAS/CH WT, 54% CPUtime in April
- No progress on DPM head node migration to SLC6 and ATLAS storage dumps
- Accounting numbers (from scheduler) from last month (Mar 2016) ( includes ce03/CLOUD )
- WC h: 1028684 (ATLAS) - 149450 (t2k.org) - 16739 (uboone) - 10776 (uboone) - 11 (ops)
- Accounting numbers (from ATLAS dashboard) from last month (Mar 2016)
- CPU h: 967738
- WC h: 1108219
UNIBE-ID
- Smooth operation the last weeks, except
- a lot of CERN jobs get killed due to h_vmem limit violation
- known issue: gridengnine counting issues with shared libraries
- no patch for (O)SGE available
- was no problem in the past (xxxx - 2015)
- no solution known (except moving to SLURM - not possible ATM); running 32-bit? only sgemaster? Experiences?
- a lot of CERN jobs get killed due to h_vmem limit violation
- Procueremnt:
- 76 new compute nodes (E5v4-10C@2.2GHz) ordered and get devlivered on 9th+10th of June
- doubling IB-Spine Switches => recabling of whole IB stuff
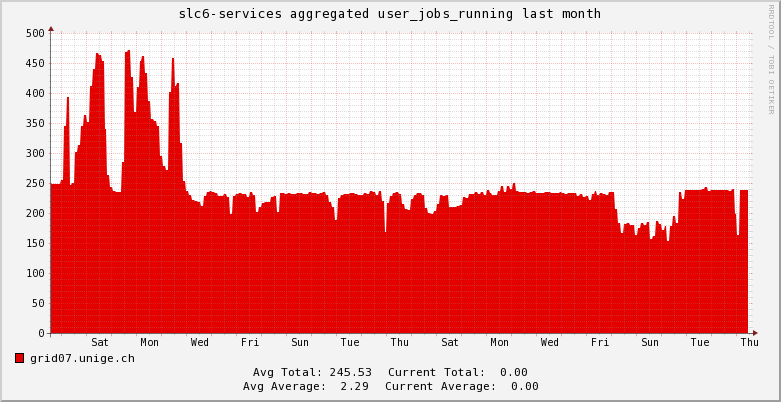
UNIGE
- Operations:
- Running smoothly with higher user usage of the cluster for last months
- 2 NFS File Servers for DPM SE with RAID controller damage: Both changed and came back into production
- ATLAS production jobs stopped since last Sunday: Contacted Gianfranco to ask about it
- Some problems with Data Management at some sites, but we were removed and not put it back until today
- A long list of action items:
- Such as CentOS,
- add WNs into the batch system,
- add new NFS File Server for ATLAS DPM SE,
- create a new pool inside DPM SE for another group: DAMPE
- Network upgrade to 10 Gb/s
- Move to SLURM for batch system and Puppet for DM SE
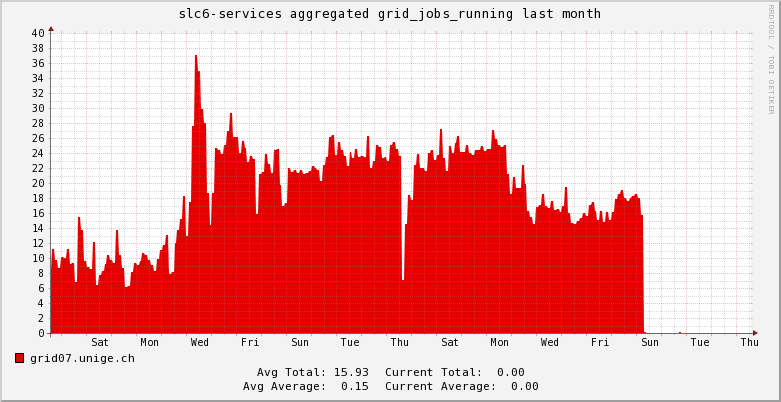
- Accounting numbers (from scheduler) from last month
NGI_CH
* Xxx * EGI mostly focussing on Fed Cloud operation consolidation * NGI-CH Open Tickets review * NGI-CH Open Tickets review: https://ggus.eu/index.php?mode=ticket_search&supportunit=NGI_CH&status=open&timeframe=any&orderticketsby=REQUEST_ID&orderhow=desc&search_submit=GO- EGI mostly focussing on Fed Cloud operation consolidation
- New MW products for CenOS 7:
- ARC
- Argus
- dcache
- fts3
- site-bdii
- top-bdii
- NGI-CH Open Tickets review: https://ggus.eu/index.php?mode=ticket_search&supportunit=NGI_CH&status=open&timeframe=any&orderticketsby=REQUEST_ID&orderhow=desc&search_submit=GO
- No ticket not touched for 1 week or more
- Changed 2 tickets from "assigned" state to "in progress"
Other topics
- Topic1
- Topic2
A.O.B.
Attendants
- CSCS:
- CMS: Fabio Martinelli
Action items
- Item1
- dcache 9k:
- e5600perf:
- sancscs:


| I | Attachment | History | Action | Size | Date |
Who | Comment |
|---|---|---|---|---|---|---|---|
| |
May12_CMS.pdf | r1 | manage | 1650.8 K | 2016-05-12 - 12:00 | JoosepPata | CMS report on computing resources |
| |
UniGe_GRID_last_month.png | r1 | manage | 41.6 K | 2016-05-12 - 12:12 | LuisMarch | Unige GRID last month |
| |
UniGe_Users_last_month.png | r1 | manage | 33.3 K | 2016-05-12 - 12:13 | LuisMarch | UniGe Users last month |
| |
e5600two.png | r1 | manage | 56.7 K | 2016-05-12 - 10:08 | DarioPetrusic | e5600perf |
| |
g07.201603.log | r1 | manage | 1.2 K | 2016-05-12 - 12:09 | LuisMarch | Unige accounting - March 2016 |
| |
g07.201604.log | r1 | manage | 1.1 K | 2016-05-12 - 12:10 | LuisMarch | UniGe accounting - April 2016 |
| |
phoenix-cscs-san.png | r1 | manage | 95.1 K | 2016-05-12 - 10:08 | DarioPetrusic | sancscs |
| |
poolqueueplots2.png | r1 | manage | 24.8 K | 2016-05-12 - 10:04 | DarioPetrusic | dcache 9k |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This topic: LCGTier2 > WebHome > MeetingsBoard > MeetingSwissGridOperations20160512
Topic revision: r12 - 2016-05-12 - LuisMarch
Ideas, requests, problems regarding TWiki? Send feedback