Swiss Grid Operations Meeting on 2019-04-04 at 14:00
- Place: Vidyo (room: Swiss_Grid_Operations_Meeting, extension: 10537598)
- External link: https://vidyoportal.cern.ch/flex.html?roomdirect.html&key=FAEn4zjAba7BqoQ11TGZu66VSDE

- Phone gate: From Switzerland: 0227671400 (portal) + 10537598 (extension) + # (pound sign)
- IRC chat: irc:gridchat.cscs.ch:994#lcg (ask pw via email)
- Switch Vidyo SIP IP: 137.138.248.204
Site status
CSCS
Storage- dCache
- New (CSCS) storage system (4x Huawei OceanStore 6800 V5, aggr. W/bw ~40GB/s, 18.1PB) has been delivered and configured (will be used also for dCache)
- Installing/configuring new 'se' nodes to start migrating data
- Will then decommission old servers and move the ones still under warranty to the new island
- Spctrum Scale
- Finalizing the plan to:
- Move from IB to 25G (need to replace card on each server) and re-configure GPFS
- Move 16 servers from old island to new island
- Move (SSD) storage from old island to new island
- Attach new exp. units to sc9000 controllers (doing only SSD now) and move GPFS "slow tier" from DDN SFA12k to sc9000
- Will need 2 days maintenance (but will do the best to make it in 1 day). Maintenance will be announced as soon as we have all things planned. Target dates are next week or the week after
- Finalizing the plan to:
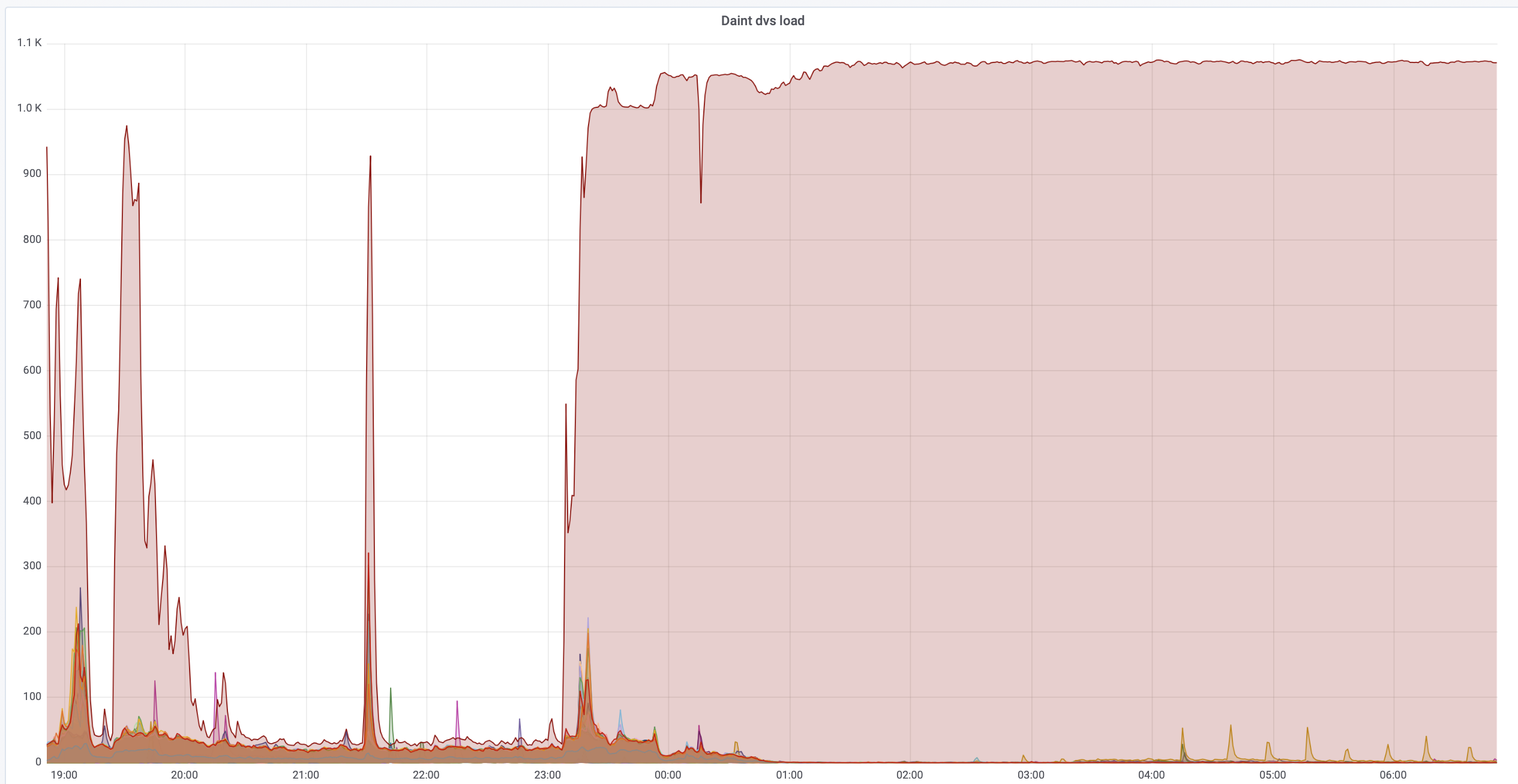
We've recently identified a number of jobs stalling or failing due to timeouts, where GPFS filesystem as seen on the compute nodes (via DVS) was very slow, at times unusable. When this was happening, typically the filesystem would stall with
mmfsd running at 400% cpu time and DVS kernel threads piling up to about 1000, effectively making the load to flatline at about 1070, which is the maximum allowed in the code of DVS kernel module.
More... Close  While debugging this, we've identified and fixed some problems:
While debugging this, we've identified and fixed some problems: - ATLAS jobs have been constantly hitting the same set of files in the ARC cache.
- This has been now fixed by copying files from the cache to the session dir.
- Analysis jobs were disabled for a few days and have now been re-enabled.
- Some LHCb jobs were stalling due to
arc04producing wrong BDII information.- Fixed by re-introducing a tuning to ARC.
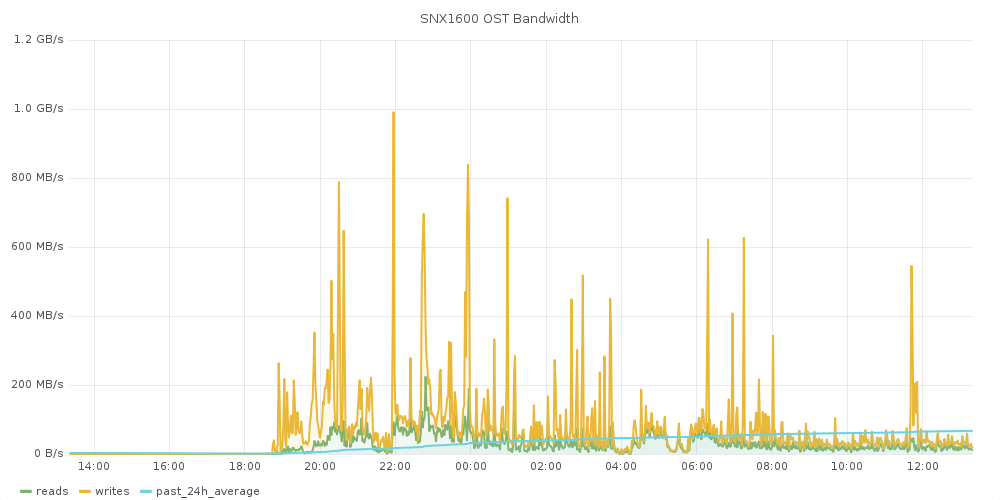
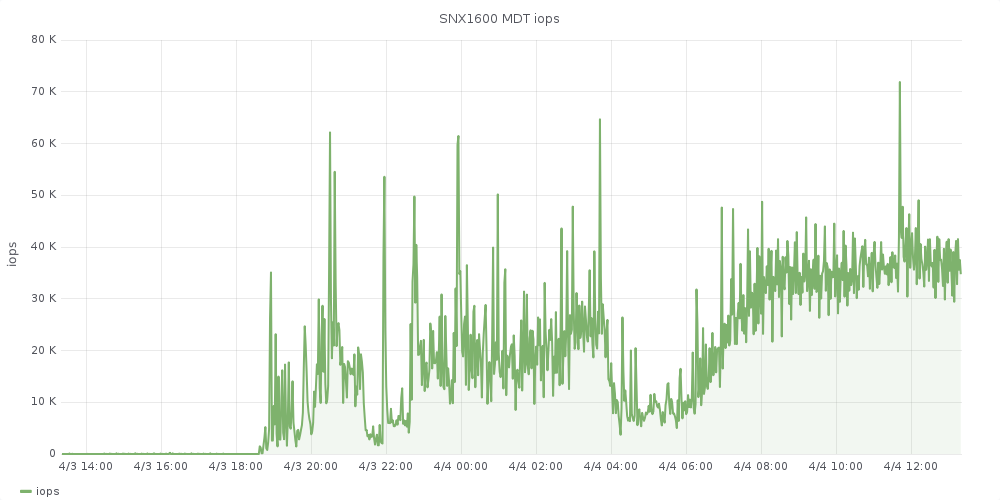
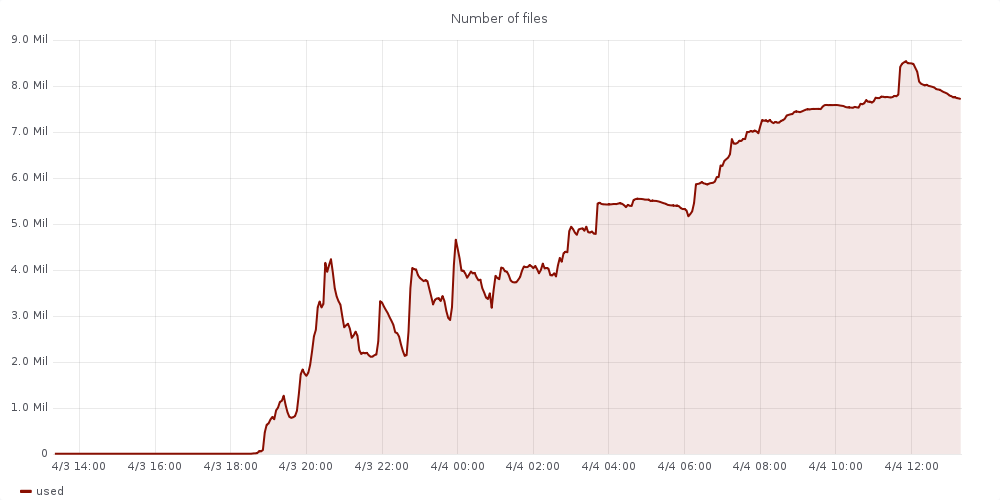
- Certain CMS jobs have been generating an unusually high number of files in very short periods of time (example: 550.000 small files in 4min).
- We've moved CMS jobs, which are mostly Analysis to an alternative scratch filesystem (Sonexion 1600, 2.7 PB Lustre) that is barely making it with the type of workload (20MB/s, 30.000 iops/s).



- We are evaluating DataWarp (again) with independent allocations per job, as well as other solutions.
- We contacted the user that we believe is the main driver of this workload, but it is now clear that we cannot easily ban a specific user from the system.
- We've moved CMS jobs, which are mostly Analysis to an alternative scratch filesystem (Sonexion 1600, 2.7 PB Lustre) that is barely making it with the type of workload (20MB/s, 30.000 iops/s).

PSI
- t3 f2f in March
- April: delivery and installation of 2nd GPU node and new WNs (test of rhel7)
- Accounting numbers (from scheduler) from last month
UNIBE-LHEP
- Xxx
- Accounting numbers (from scheduler) from last month
UNIBE-ID
- Xxx
UNIGE
- Xxx
- Accounting numbers (from scheduler) from last month
NGI_CH
- Xxx
- NGI-CH Open Tickets review
Other topics
- Topic1
- Topic2
A.O.B.
Attendants
- CSCS:
- CMS:
- ATLAS:
- LHCb:
- EGI:
Action items
- Item1


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
dvsload.png | r1 | manage | 393.0 K | 2019-04-04 - 11:17 | MiguelGila | DVS load flatlining at ~1000 |
| |
snx1600-2.png | r1 | manage | 69.5 K | 2019-04-04 - 11:22 | MiguelGila | |
| |
snx1600-3.png | r1 | manage | 64.1 K | 2019-04-04 - 11:22 | MiguelGila | |
| |
snx1600.png | r1 | manage | 32.2 K | 2019-04-04 - 11:22 | MiguelGila |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This topic: LCGTier2 > WebHome > MeetingsBoard > MeetingSwissGridOperations20190404
Topic revision: r4 - 2019-04-04 - NinaLoktionova
Ideas, requests, problems regarding TWiki? Send feedback