
Go to
previous page /
next page of CMS site log

25. 05. 2009 STEP09
Analysis exercises
central monitoring
Table entries taken from central
T2 STEP09 analysis page
Note: The low values for
Percentage of Analysis Pledge Used have the primary reason of not enough jobs being sent. However, we should watch out for conditions where a VO cannot get their assigned resources in appreciable time.
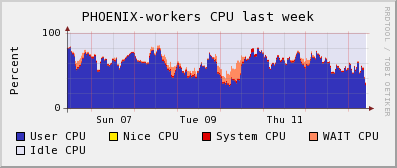
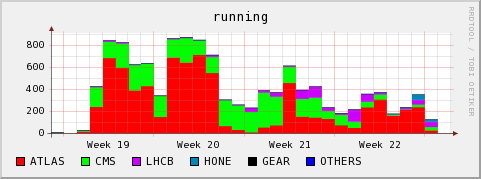
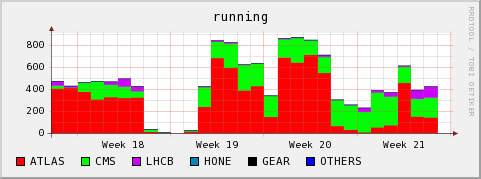
local monitoring
Note: On Monday June 8 I became aware of the local monitoring ignoring ATLAS pilot and nordugrid jobs. One can still derive the approx. number of jobs by looking whether there were any queued jobs at a time, and then assuming that the running job queue must have been filled to the top with these jobs.
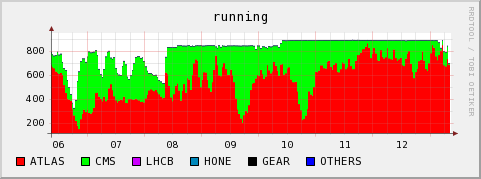
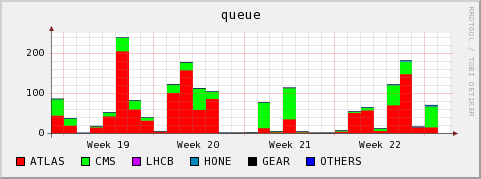
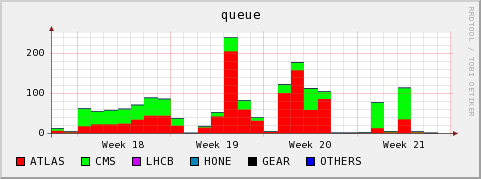
Running and queued jobs

dcap and gsiftp movers
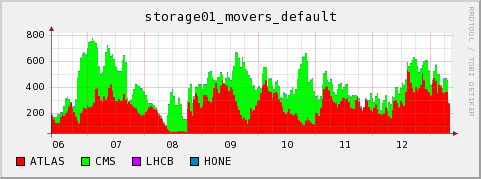
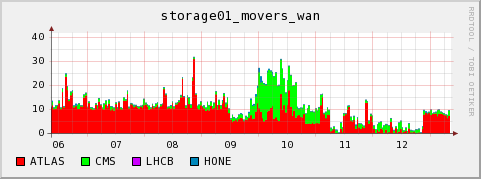
During week 22 we noticed two conditions disturbing the cluster
- There were ATLAS jobs which did heavy prestaging of files from the SE to the WN using dccp. Many nodes ended up with massive I/O wait due to the many dccp processes fighting for the bandwidth and the access to the local scratch space.
- ATLAS then shifted away from using dccp, afterwards seemingly using direct dcap. It seems to me that this is still a strange theoretical payload. The ratio of I/O to CPU is excessive.
- An ATLAS user had reserved 16CPUs for his jobs, without actually making use of them. This blocked the queue and is the explanation for the queued jobs in the above graphs despite only a subset of our actual cores being taken.
Data transfers
Evaluation of the exercise
This is based on the monitoring, below.
First day: Very nice high quality throughput from FNAL. In the first 12 h I had avg. speed of about 70 MB/s. Problems with
IN2P3 (their SE had an error which failed half of the transfers). No Files at all from our dedicated T1 at FZK???
Second day: Still good transfers from FNAL, albeit somewhat slower. One big set finished. Some files from FZK, but at slow speed (~5 MB/s on avg.). Still about 50% failures from
IN2P3, a big fraction still with the "gsiftp protocol not supported" error.
ordered datasets and simple latency observations
I approved the following two requests on 2009-06-10, 19:45:
Request 51292
| Data Level |
Data Item |
SRC |
Files |
Size |
06/10 15:25h |
06/11 9:20h |
06/11 18:30h |
| Dataset |
/Wc-madgraph/Fall08_IDEAL_V9_v1/GEN-SIM-RAW |
T1_DE_FZK |
3254 |
3.13 TB |
0 |
294 (289.1GB) |
303 (297.9GB) |
| Dataset |
/Wc-madgraph/Fall08_IDEAL_V11_redigi_v1/GEN-SIM-RAW |
T1_DE_FZK |
3156 |
3.01 TB |
0 |
0 |
0 |
Request 51297
| Data Level |
Data Item |
Files |
Size |
SRC |
06/10 9:40h |
06/10 15:25h |
06/11 9:20h |
06/11 18:30h |
| Dataset |
/QCD100to250-madgraph/Fall08_IDEAL_V11_redigi_v1/GEN-SIM-RECO |
T1_US_FNAL |
4099 |
4.26 TB |
2505 (2.6 TB) |
3718 (3.9TB) |
4099 (4.3TB) |
- |
| Dataset |
/InclusivePPmuX/Summer08_IDEAL_V11_redigi_v1/GEN-SIM-RECO |
T1_ES_PIC, T1_FR_CCIN2P3, |
1702 |
1.47 TB |
878 (0.7TB) |
1255 (1.1TB) |
1326 (1.1TB) |
1346 (1.2TB) |
- Note: The SRC column shows the sites with direct links to T2_CH_CSCS that DBS marks as having the sets.
Phedex central monitoring
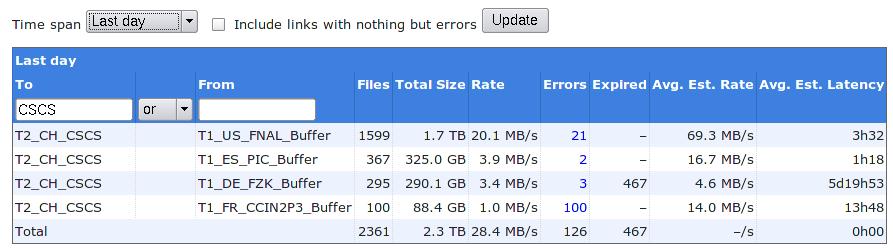
Phedex central monitoring for last day (taken on 2009-06-11 9:25h):
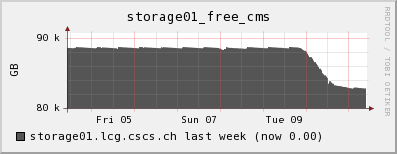
My own local phedex monitoring:
Error message statistics per site:
 Show
Show  Hide
Hide
===================================
*** ERRORS from T1_ES_PIC_Buffer:***
6 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] globus_ftp_client: the server responded with an error 426 Transfer aborted (Transfer failed: Connection timed out)
*** ERRORS from T1_FR_CCIN2P3_Buffer:***
480 SOURCE error during TRANSFER_PREPARATION phase: [GENERAL_FAILURE] Protocol(s) specified not supported: [ gsiftp ]
8 SOURCE error during TRANSFER_PREPARATION phase: [REQUEST_TIMEOUT] failed to prepare source file in 180 seconds
2 SOURCE error during TRANSFER phase: [GRIDFTP_ERROR] an end-of-file was reached globus_xio: An end of file occurred (possibly the destination disk is full)
2 SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out
*** ERRORS from T1_US_FNAL_Buffer:***
9 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] globus_ftp_client: the server responded with an error 426 Transfer aborted (Unexpected Exception : org.dcache.ftp.FTPException: Stream ended before EOD/Data channel was closed before EOD marker)
3 SOURCE error during TRANSFER phase: [GRIDFTP_ERROR] globus_xio: Unable to connect to cmsstor68.fnal.gov:2811 globus_xio: System error in connect: Connection refused globus_xio: A system call failed: Connection refused
2 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] an end-of-file was reached globus_xio: An end of file occurred (possibly the destination disk is full)
1 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] globus_ftp_client: the server responded with an error 426 Transfer aborted (Transfer failed: Connection reset by peer)
SITE STATISTICS:
==================
first entry: 2009-06-09 07:37:07 last entry: 2009-06-10 07:36:12
T1_ES_PIC_Buffer (OK: 190 Err: 6 Exp: 0 Canc: 0 Lost: 0) succ.: 96.9 % total: 180.5 GB ( 2.1 MB/s)
T1_FR_CCIN2P3_Buffer (OK: 688 Err: 492 Exp: 0 Canc: 0 Lost: 0) succ.: 58.3 % total: 652.5 GB ( 7.6 MB/s)
T1_US_FNAL_Buffer (OK: 2525 Err: 15 Exp: 0 Canc: 0 Lost: 0) succ.: 99.4 % total: 2895.0 GB (33.5 MB/s)
TOTAL SUMMARY:
==================
first entry: 2009-06-09 07:37:07 last entry: 2009-06-10 07:36:12
total transferred: 3472.0 GB in 24.0 hours
avg. total rate: 41.2 MB/s = 329.4 Mb/s = 3474.2 GB/day
Error message statistics per site:
Show Hide
===================================
*** ERRORS from T1_DE_FZK_Buffer:***
2 SOURCE error during TRANSFER phase: [TRANSFER_TIMEOUT] globus_ftp_client_size: Connection timed out
1 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] globus_xio: System error in read: Connection reset by peer globus_xio: A system call failed: Connection reset by peer
*** ERRORS from T1_ES_PIC_Buffer:***
1 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] globus_ftp_client: the server responded with an error 426 Transfer aborted (Transfer failed: Connection timed out)
*** ERRORS from T1_FR_CCIN2P3_Buffer:***
35 SOURCE error during TRANSFER phase: [GRIDFTP_ERROR] an end-of-file was reached globus_xio: An end of file occurred (possibly the destination disk is full)
20 SOURCE error during TRANSFER_PREPARATION phase: [GENERAL_FAILURE] Protocol(s) specified not supported: [ gsiftp ]
5 SOURCE error during TRANSFER_PREPARATION phase: [REQUEST_TIMEOUT] failed to prepare source file in 180 seconds
*** ERRORS from T1_US_FNAL_Buffer:***
9 error during phase: []
7 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] an end-of-file was reached globus_xio: An end of file occurred (possibly the destination disk is full)
5 TRANSFER error during TRANSFER phase: [GRIDFTP_ERROR] globus_ftp_client: the server responded with an error 426 Transfer aborted (Unexpected Exception : org.dcache.ftp.FTPException: Stream ended before EOD/Data channel was closed before EOD marker)
SITE STATISTICS:
==================
first entry: 2009-06-10 07:35:51 last entry: 2009-06-11 07:35:22
T1_DE_FZK_Buffer (OK: 295 Err: 3 Exp: 0 Canc: 0 Lost: 0) succ.: 99.0 % total: 311.5 GB ( 3.6 MB/s)
T1_ES_PIC_Buffer (OK: 348 Err: 1 Exp: 0 Canc: 0 Lost: 0) succ.: 99.7 % total: 331.3 GB ( 3.8 MB/s)
T1_FR_CCIN2P3_Buffer (OK: 100 Err: 60 Exp: 0 Canc: 0 Lost: 0) succ.: 62.5 % total: 94.9 GB ( 1.1 MB/s)
T1_US_FNAL_Buffer (OK: 1594 Err: 21 Exp: 0 Canc: 0 Lost: 0) succ.: 98.7 % total: 1814.1 GB (21.0 MB/s)
TOTAL SUMMARY:
==================
first entry: 2009-06-10 07:35:51 last entry: 2009-06-11 07:35:22
total transferred: 2376.5 GB in 24.0 hours
avg. total rate: 28.2 MB/s = 225.4 Mb/s = 2377.3 GB/day
Note: Measurement for first 12 hours showing high rates with top quality from FNAL.
Show Hide
SITE STATISTICS:
==================
first entry: 2009-06-09 19:00:32 last entry: 2009-06-10 07:00:32
T1_CH_CERN_Buffer (OK: 8 Err: 0 Exp: 0 Canc: 0 Lost: 0) succ.: 100.0 % total: 21.5 GB ( 0.5 MB/s)
T1_ES_PIC_Buffer (OK: 105 Err: 2 Exp: 0 Canc: 0 Lost: 0) succ.: 98.1 % total: 113.5 GB ( 2.6 MB/s)
T1_FR_CCIN2P3_Buffer (OK: 671 Err: 422 Exp: 0 Canc: 0 Lost: 0) succ.: 61.4 % total: 645.7 GB (14.9 MB/s)
T1_IT_CNAF_Buffer (OK: 6 Err: 0 Exp: 0 Canc: 0 Lost: 0) succ.: 100.0 % total: 16.1 GB ( 0.4 MB/s)
T1_TW_ASGC_Buffer (OK: 8 Err: 2 Exp: 0 Canc: 0 Lost: 0) succ.: 80.0 % total: 22.5 GB ( 0.5 MB/s)
T1_UK_RAL_Buffer (OK: 8 Err: 0 Exp: 0 Canc: 0 Lost: 0) succ.: 100.0 % total: 22.3 GB ( 0.5 MB/s)
T1_US_FNAL_Buffer (OK: 2412 Err: 15 Exp: 0 Canc: 0 Lost: 0) succ.: 99.4 % total: 2803.3 GB (64.9 MB/s)
T2_DE_RWTH (OK: 0 Err: 0 Exp: 37 Canc: 0 Lost: 0) total: 0.0 GB ( 0.0 MB/s)
TOTAL SUMMARY:
==================
first entry: 2009-06-09 19:00:32 last entry: 2009-06-10 07:00:32
total transferred: 3394.5 GB in 12.0 hours
avg. total rate: 80.5 MB/s = 643.7 Mb/s = 6789.1 GB/day
Events happening on the cluster
2009-05-20/21 SRM queue overfilled by thousands of GET requests from ATLAS jobs
Jobs from two users (one is from the ATLAS central operations responsible for the STEP09
HammerCloud pre-tests) caused the SRM queue to grow by several jobs a second. In the SRM-storage01 cell we had to put maxReadyJobs=3000 to keep the site up for the meantime. One user we had to ban temporarily, until Hurng-Chun Lee from ATLAS traced back the problem to a python routine trying to calculate the adler32 checksum by reading in the full file into a python string (and overstepping the python boundary on these systems), therby hanging the system in a bad way. This was corrected.
2009-05-29 ATLAS heavy staging to local disc by dccp impacts cluster
We saw heavy dcap activity and many CPUs with significant I/O wait states. Some nodes actually became unresponsive. This was traced back to multiple dccp processes running on every node and writing to local disk. dccp is used to copy whole files per dcap from the SE, so ATLAS seems to follow a model where they first stage the whole file to local disk. However, our cluster is laid out for analysis jobs to read directly via dcap from the storage.
This was not a problem, before, because like many dcache sites we limit the gridftp transfers to a few per pool, because these do high efficiency sequential reads which are more efficient when scheduled sequentially. We allow many more dcap movers in the assumption that jobs using these usually will keep open the filehandle for reading sparsely. But if people use dccp for staging, they get the dcap mover limit, resulting in a max of 100 movers per pool in our configuration!!!
Todays nodes tend to have more and more cores and less disks per core (our current cluster has blade nodes with 16 cores, but only one scratch disk - certainly not ideal). It is bad policy to have many jobs stage files locally, which thereafter are maybe read sparsely. Also, it is bad if all kinds of jobs stage the identical files to local disk. Also, it seemed to me that the ganga robot staged all the files for the whole job at the beginning instead of getting one, processing one, and then getting the next.
After contacting ATLAS (Johannes Elmsheuser and Hurn-Chun Lee) they disabled the usage of dccp in Ganga.
Over the next days we still saw high numbers of dcacp movers and I/O wait on nodes running ATLAS jobs, but seemingly this was now truly using dcap internally. Still, it seems that the jobs have very low processing in comparison to I/O (maybe almost empty loops over events?). Never seen that in CMS jobs up to now. Disruptive to the efficiency of the cluster.
If these are real payloads, we need to reconsider the design of the cluster.
Our monitoring points to pilot jobs being the most troublesome (may also be nordugrid).
2009-06-07/08 Three WNs acting as black holes during the night
Three nodes went down with disk failures. Unluckily the batch system still considered them as eligible. Here we see a design weakness in our cluster. We have 16 cores per blade node, but only two disks. One disk is for the OS, while there is only one scratch disk. Especially in a mode where all jobs seem to do heavy staging to local disk (like the ATLAS jobs we see), the disks are exercised to their limit. We will try to repair these deficiencies in the next upgrade which is under planning, now.
--
DerekFeichtinger - 25 May 2009
Go to
previous page /
next page of CMS site log



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}