Tags:
view all tags
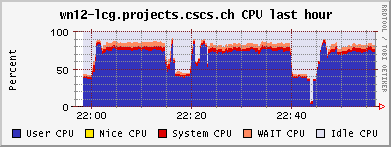
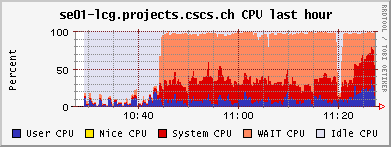
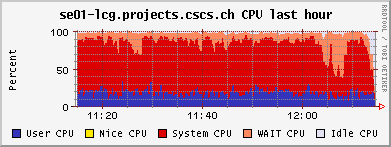
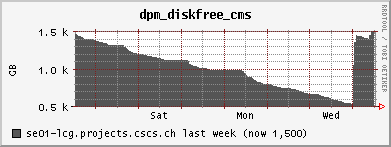
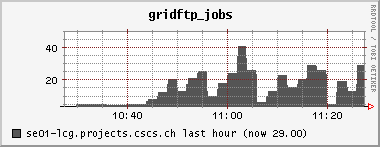
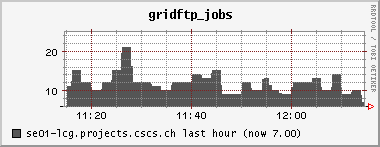
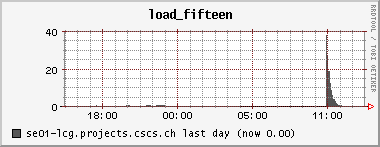
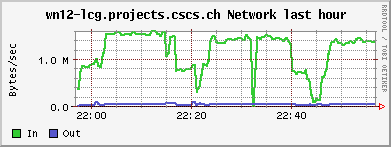
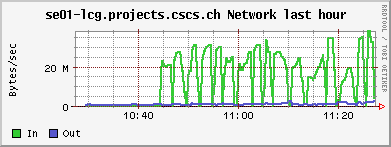
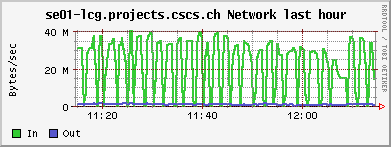
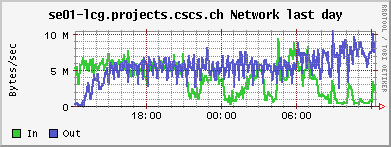
<!-- keep this as a security measure: * Set ALLOWTOPICCHANGE = Main.TWikiAdminGroup,Main.LCGAdminGroup,Main.CMSAdminGroup * Set ALLOWTOPICRENAME = Main.TWikiAdminGroup,Main.LCGAdminGroup #uncomment this if you want the page only be viewable by the internal people * #Set ALLOWTOPICVIEW = Main.TWikiAdminGroup,Main.LCGAdminGroup --> ---+ !!CMS CSA06 Site Log for PHOENIX Cluster %TOC% %ICON{arrowleft}% Go to [[SC4SiteLogCMS2][previous page]] / next page of CMS site log %M% ---++ 6. 10. 2006 Many failures due to permissions problem - FIXED Came back from a few days of vacation and discovered lots of failures on our CSCS !PhEDEx download agent. It's an old problem: The directory /dpm/projects.cscs.ch/home/cms/trivcat/store/CSA06 had automatically been created during production by Carsten with the production VOMS-role, while !PhEDEx agents from FZK now try to write with a "naked" proxy that just gets mapped to group cms. In DPM the groups "cms/Role=production" and "cms" are understood as completely different groups. There is no hierarchy of groups possible. Additional permissions can be set by hand using =dpns-setacl=, which is fine, as long as the different roles constrain themselves to write in well separated branches of the directory tree. So, only a few high level directories need to be changed by a manager. It would be optimal, if the authorization modules of the storage services understood group hierarchies... (also look at [[https://hypernews.cern.ch/HyperNews/CMS/get/sc4/231.html][this hypernews thread]]) After changing the permissions of the directory, the transfers immediately started to work, although pushing our SE to the limit: <br /><img src="%ATTACHURLPATH%/cpu20061006.gif" alt="cpu20061006.gif" width='391' height='147' /> <br /><img src="%ATTACHURLPATH%/network20061006.gif" alt="network20061006.gif" width='391' height='147' /> <br /><img src="%ATTACHURLPATH%/gridftp20061006.gif" alt="gridftp20061006.gif" width='391' height='147' /> The !PhEDEx settings of the download agent are <verbatim> -batch-files 5 -jobs 2 </verbatim> while the FTS channel parameters are set to <verbatim> Bandwidth: 0 Nominal throughput: 0 Number of files: 5, streams: 1 </verbatim> 8. 10. 2006: *Success rate for the transfers from FZK is basically 100%* (repeated failures yesterday were due to a wrong file length value in the central DB)! Peak transfer rates for some single files are ~ 150Mb/s = 20MB/s. ---++ 9. 10. 2006 strange myproxy problem - FIXED A configuration problem on the FTS server at FZK caused an error condition, where all of our download transfers failed due to not being able to obtain a myproxy certificate. I was not able to reproduce this failure when trying myself to check the certificate delegation using myproxy tools: <verbatim> $> myproxy-info -d -s myproxy-fts.cern.ch username: /O=GRID-FR/C=CH/O=CSCS/OU=CC-LCG/CN=Derek Feichtinger owner: /O=GRID-FR/C=CH/O=CSCS/OU=CC-LCG/CN=Derek Feichtinger timeleft: 719:53:34 (30.0 days) $> myproxy-get-delegation -v -l "/O=GRID-FR/C=CH/O=CSCS/OU=CC-LCG/CN=Derek Feichtinger" -s myproxy-fts.cern.ch -o /tmp/gagaga Enter MyProxy pass phrase: Socket bound to port 20002. server name: /C=CH/O=CERN/OU=GRID/CN=host/lxb0728.cern.ch checking if server name matches "myproxy@lxb0728.cern.ch" server name does not match checking if server name matches "host@lxb0728.cern.ch" server name accepted A proxy has been received for user /O=GRID-FR/C=CH/O=CSCS/OU=CC-LCG/CN=Derek Feichtinger in /tmp/gagaga </verbatim> Martin Litmaath suggested, that the problem was due to a missing setting in the environment on the VO agent node at FZK: =MYPROXY_TCP_PORT_RANGE 20000,25000=. This solved it, so I restarted our !PhEDEx download agent. The current downloads are quite efficient. As can be seen from the following ganglia plots, the transfers have a constant throughput. Also the CPU is now used much more efficiently as last month (maybe because we have now more disks in the machine and I opened up the pools?). <br /><img src="%ATTACHURLPATH%/cpu20061011.gif" alt="cpu20061011.gif" width='391' height='147' /> <br /><img src="%ATTACHURLPATH%/network20061011.gif" alt="network20061011.gif" width='391' height='147' /> <br /><img src="%ATTACHURLPATH%/gridftp20061011.gif" alt="gridftp20061011.gif" width='391' height='147' /> ---++ 19. 10. 2006 Transfers stable - about 1 TB/week The transfers seem to go pretty smoothly. Yesterday, the CMS pool on our SE only had 500 GB left, but following a message of Ian Fisk, I was able to erase the /store/CSA06/CSA06-102-os-minbias-0 data set. The CMS pool graph below shows that we are currently geting rather stably about 1 TB/week from FZK. <br /><img src="%ATTACHURLPATH%/dpm_diskfree_cms20061019.gif" alt="dpm_diskfree_cms20061019.gif" width='391' height='147' /> <verbatim> SITE STATISTICS: for 2006-10-14 00:09:27 until 2006-10-20 10:08:49 ================== site: T1_FZK_Buffer (OK: 328 / FAILED: 28) success rate: 92.1348314606742% site: T1_FNAL_Buffer (OK: 44 / FAILED: 12) success rate: 78.5714285714286% Errors: 1 T1_FZK_Buffer: Failed Failed on SRM get: SRM getRequestStatus timed out on get; 2 T1_FZK_Buffer: Failed Failed on SRM put: Failed SRM put on httpg://se01-lcg.projects.cscs.ch:8443/srm/managerv1 ; Error is File exists; 10 T1_FNAL_Buffer: Canceled (null); 25 T1_FZK_Buffer: Failed Failed on SRM get: Cannot Contact SRM Service. Error in srm__ping: SOAP-ENV:Client - CGSI-gSOAP: Error reading token data: Success; </verbatim> ---++ 26. 10. 2006 Very bad transfer quality from FZK Since approximately the time of the dcache update at FZK, the transfer quality is consistently bad. I can see that all transfers from FZK share this problem. Notified the FZK admins <verbatim> SITE STATISTICS: 2006-10-26 05:20:53 to 2006-10-26 12:41:29 ================== site: T1_FZK_Buffer (OK: 1 / FAILED: 16) success rate: 5.88235294117647% site: T1_FNAL_Buffer (OK: 12 / FAILED: 13) success rate: 48% Errors: 1 T1_FZK_Buffer: Failed Failed on SRM get: SRM getRequestStatus timed out on get; 4 T1_FZK_Buffer: Canceled (null); 8 T1_FZK_Buffer: Failed Transfer failed. ERROR the server sent an error response: 425 425 Can't open data connection. timed out() failed.; 7 T1_FNAL_Buffer: Canceled (null); </verbatim> Note: the _425 425 Can't open_ error is again the most prominent error. ---++ 29. 10. 2006 SE services breakdown - still trouble with FZK transfers This morning around 5 am it seems that again the SE ran out of memory and was unable to spawn any new processes. Monitoring information from 5 am until about noon is missing, which suggests that no process for the ganglia collecting and sending of data was able to launch. Based on the two following monitoring graphs, it seems again that a small number of processes hijacked the whole memory. <br /><img src="%ATTACHURLPATH%/memory20061029.gif" alt="memory20061029.gif" width='391' height='160' /> <br /><img src="%ATTACHURLPATH%/load_fifteen-20061029.gif" alt="load_fifteen-20061029.gif" width='380' height='147' /> The system recovered by itself, but the SE services have died. Apart from that we still have severe problems with transfers from FZK. The admins there told us that they have difficulties with the gridftp doors of their new dcache version. We almost get no data at the moment :-( ---++ 30. 10. 2006 SE services restarted, again huge memory consumption at night 23:30h: There is again a dpm.ftpd process with huge memory consumption (takes up much swap space. 2.79 GB). Local process owner is cms016. Looking at the process reveals that it has a read mode file descriptor to a CMS file with length 2839158582 Bytes. The fd points to =/storage/cms/cms/2006-10-28/2C4599BC-1861-DB11-B16E-0002B3D8E597.root.853039.0=. There is a number of established sockets to FZK: =se01-lcg.projects.cscs.ch:20009->f01-015-107-e.gridka.de:20014= Need to find out how to map that to the CMS LFN in the DPM DB. In the !PhEDEx web monitoring pages ([[http://cmsdoc.cern.ch/cms/aprom/phedex/prod/Activity::TransferStates?tofilter=&andor=or&fromfilter=CSCS][transfer details]]) I can see an active transfer from CSCS to FZK. The file length matches exactly the above job. <verbatim> lfn=/store/CSA06/CSA06-105-os-minbias-0/RECO/CMSSW_1_0_5-RECO-H746ee88eddaa52306cd016b2f689e370/1021/ 2C4599BC-1861-DB11-B16E-0002B3D8E597.root size=2839158582 errors=0 from_pfn=srm://se01-lcg.projects.cscs.ch:8443/srm/managerv1?SFN=/dpm/projects.cscs.ch/home/cms/trivcat/store/ CSA06/CSA06-105-os-minbias-0/RECO/CMSSW_1_0_5-RECO-H746ee88eddaa52306cd016b2f689e370/ 1021/2C4599BC-1861-DB11-B16E-0002B3D8E597.root to_pfn=srm://gridka-dCache.fzk.de:8443/srm/managerv1?SFN=/pnfs/gridka.de/cms/disk-only/Prod/store/CSA06/ CSA06-105-os-minbias-0/RECO/CMSSW_1_0_5-RECO-H746ee88eddaa52306cd016b2f689e370/ 1021/2C4599BC-1861-DB11-B16E-0002B3D8E597.root time_xfer_start=2006-10-30 18:49:09 UTC </verbatim> The transfer process is completely dormant - I see no activity. Killed the process as a safety measure. So, it seems that the problematic processes are hanging dpm.ftpd processes exporting files to the outside. A big part of the file gets memory mapped. Obviously the timeout set by the receiving end is much to high. Not clear why the transfer is stuck. ---++ 1. 11. 2006 FZK seems ok again, good transfer quality from FNAL FZK site admins reported that their dcache pool is working again. There have been only 5 !PhEDEx Transfers during this night. They were all successful, but at low transfer rates. Our best source is now FNAL, but with equally low transfer rates. At least the success rates are now reassuring. <verbatim> SITE STATISTICS: ================== start: 2006-10-31 21:21:06 end: 2006-11-01 12:35:36 site: T1_FZK_Buffer (OK: 5 / FAILED: 0) success rate: 100% avg. rate: 4.01 Mb/s site: T1_FNAL_Buffer (OK: 95 / FAILED: 0) success rate: 100% avg. rate: 3.84 Mb/s </verbatim> Currently we have no !JobRobot information. This may either be due to the needed samples not being yet on site, or CE having disappeared for some time from the BDII, or problems of the !JobRobot itself. As soon as we have the needed samples, I will investigate. 23h: Seems we are served again by the the !JobRobot. Here are some plots of a worker node running two CMS !JobRobot jobs: <br /><img src="%ATTACHURLPATH%/network-wn12-20061101.gif" alt="network-wn12-20061101.gif" width='391' height='147' /> <br /><img src="%ATTACHURLPATH%/cpu-wn12-20061101.gif" alt="cpu-wn12-20061101.gif" width='391' height='147' /> This amounts to ~600 kB/s rfio read access per job. ---++ 2. 11. 2006 Transfers from other T1s (almost nothing routed from FZK), !JobRobot ok All !JobRobot jobs of yesterdays submission for CSCS were successful, so the situation is getting back to normal ([[https://hypernews.cern.ch/HyperNews/CMS/get/csa06/189.html][hypernews message]]) !PhEDEx: <verbatim> SITE STATISTICS: ================== start: 2006-11-02 15:45:23 end: 2006-11-02 22:14:29 site: T1_CNAF_Buffer (OK: 0 / FAILED: 2) success rate: 0% site: T1_FZK_Buffer (OK: 1 / FAILED: 0) success rate: 100% avg. rate: 4.23 Mb/s site: T1_RAL_Buffer (OK: 22 / FAILED: 0) success rate: 100% avg. rate: 1.70 Mb/s site: T1_ASGC_Buffer (OK: 0 / FAILED: 5) success rate: 0% site: T1_IN2P3_Buffer (OK: 1 / FAILED: 18) success rate: 5.26315789473684% avg. rate: 4.11 Mb/s site: T1_FNAL_Buffer (OK: 3 / FAILED: 0) success rate: 100% avg. rate: 3.21 Mb/s Errors: 13 T1_IN2P3_Buffer: Failed Failed on SRM get: Cannot Contact SRM Service. Error in srm__ping: SOAP-ENV:Client - CGSI-gSOAP: Error reading token data: Success; 3 T1_IN2P3_Buffer: Failed SRMGETDONE Operation Timed out.; 1 T1_IN2P3_Buffer: Failed Failed on SRM get: Failed To Get SURL. Error in srm__get: SOAP-ENV: Client - CGSI-gSOAP: Error reading token data: Success; 2 T1_CNAF_Buffer: Canceled Failed on SRM get: SRM getRequestStatus timed out on get; 5 T1_ASGC_Buffer: Canceled (null); </verbatim> Slower !PhEDEx transfer speeds may be connected to the larger amount of rfio accesses from the !JobRobot jobs to the SE, as can be seen from the following plots (more time spent in CPU wait state): <br><img src="%ATTACHURLPATH%/network20061102.gif" alt="network20061102.gif" width='391' height='147' /> <br><img src="%ATTACHURLPATH%/rfio20061102.gif" alt="rfio20061102.gif" width='380' height='147' /> <br /><img src="%ATTACHURLPATH%/cpu20061102.gif" alt="cpu20061102.gif" width='391' height='147' /> ---++ 6. 11. 2006 SE disk array failure CSCS admins reported a failure of the disk array. The rebuilding of the RAID set took until the following day. The DPM was afterwards in a strange state where it tried to assign files to already full pools. This resulted in some transfers reporting "no space" errors. When looking at the lines containing =selectfs= strings in =/var/log/dpm/log=, it becomes clear that DPM internally calculates a wrong space value for the pools (although =dpm-qryconfig= returns the correct values). A restart of all DPM services seemed to fix the problem for now... ---++ 10. 11. 2006 SFT JS problem seems solved, problem to complete some !PhEDEx transfers, FTS reconfiguration We had experienced frequent SFT (site functional tests) problems over the course of the last weeks. The _job submission_ test (JS) would sometimes fail, and there was no correlation to the load of the system. Since today it looks fine. Could have well been an external problem. #AnchorMissingBlocks There is a number of file blocks which !PhEDEx fails to fetch for us. I looked up some of the blocks most interesting to our users in DLS: One of the blocks does seemingy not exist in DLS or has never bee properly registered ([[https://hypernews.cern.ch/HyperNews/CMS/get/phedex/731.html][details]] in hypernews thread). <verbatim> 1 File missing from /CSA06-103-os-TTbar0-0/CMSSW_1_0_4-hg_HiggsTau_1lFilter-1161090157 1 File missing from block #304c5276-0b20-4879-83ae-35df3c445a3d DLS locations: cmsdcache.pi.infn.it, srm-dcache.desy.de /CSA06-103-os-EWKSoup0-0/CMSSW_1_0_6-hg_Tau_Zand1lFilter-1161784687: 45 Files missing from block#64a3bb4b-aa7d-4b5c-ad4d-1bcf71166619 DLS locations: castorsc.grid.sinica.edu.tw, cmsdcache.pi.infn.it /CSA06-103-os-EWKSoup0-0/CMSSW_1_0_4-hg_HiggsTau_1lFilter-1161045561: 42 Files missing from block #9e446bfb-9c6b-4571-85b3-84fcc7969183 DLS locations: cmsdcache.pi.infn.it, gfe02.hep.ph.ic.ac.uk, srm-dcache.desy.de 70 Files missing from #7fba0245-195d-45ee-9268-e9a683136cba NO LOCATIONS FOUND IN DLS </verbatim> In regard to the block missing from DLS, [[https://hypernews.cern.ch/HyperNews/CMS/get/phedex/731/2/1.html][from PhEDEx operations Team]] (Dimitrije Maletic): <verbatim> From TMDB I got that some of the missing files (you are missing 70) are replicated also at: T2_Pisa_Buffer - Missing 22 files T2_London_IC_HEP - Missing 21 files T2_DESY_MSS - Missing 28 files T2_RutherfordPPD >> But You can't get them because they are not at any other T1 if they are lost at CNAF. </verbatim> Many of the transfers now come from =T1_ASGC_Buffer=. Since the transfer speed from Taiwan is much lower, I had to set up the timeout to 3h(!). Also, I configured the STAR-CSCS FTS channel to =Number of files 1, streams 5=. This should increase the transfer speed. The !PhEDEx parameter =-batch-files= I reduced to 3, which also reduces the transfer time per batch (the timeouts are defined per batch, not per file). Transfer quality is not bad, but transfer rates are only in the 1-5 Mb/s range. ---++ 13. 11. 2006 Persistent transfer problems from CNAF I see persistent failures from =T1_CNAF_Buffer=. All terminate with error <verbatim> Failed Failed on SRM get: SRM getRequestStatus timed out on get; </verbatim> Information from Jose Hernandez: _the problem is the same for all sites trying to get some data from CNAF. Due to a bug in castor-2 at CNAF there are problems retrieving some data from tape._ Unfortunately the files we would need to complete some of the sets need to be transfered from CNAF :-( We managed to (almost) complete three of the missing blocks mentioned [[#AnchorMissingBlocks][above]] * /CSA06-103-os-TTbar0-0/CMSSW_1_0_4-hg_HiggsTau_1lFilter-1161090157 complete * /CSA06-103-os-EWKSoup0-0/CMSSW_1_0_6-hg_Tau_Zand1lFilter-1161784687 * #64a3bb4b-aa7d-4b5c-ad4d-1bcf71166619 1 file missing * /CSA06-103-os-EWKSoup0-0/CMSSW_1_0_4-hg_HiggsTau_1lFilter-1161045561 * #9e446bfb-9c6b-4571-85b3-84fcc7969183 complete * #7fba0245-195d-45ee-9268-e9a683136cba still 70 files missing (see [[#AnchorMissingBlocks][above]] for reason) ---++ 16. 11. 2006 Not getting any more transfers (CNAF castor2 problem) Updated yesterday night to !PhEDEx-2.4.2. For the last two days we have received no more data. CNAF is currently the only available supplier for our subscriptions and all attempts still fail. We also need to be careful about space (I opened up one more 1.7TB pool, but this I can do only temporarily because it is owned by another VO). ------- %ICON{arrowleft}% Go to [[SC4SiteLogCMS2][previous page]] / next page of CMS site log %M% -- Main.DerekFeichtinger - 16 Nov 2006
Attachments
Attachments
Topic attachments
I
Attachment
History
Action
Size
Date
Who
Comment
gif
cpu-wn12-20061101.gif
r1
manage
11.6 K
2006-11-01 - 21:59
DerekFeichtinger
gif
cpu20061006.gif
r1
manage
12.3 K
2006-10-06 - 09:47
DerekFeichtinger
gif
cpu20061011.gif
r1
manage
11.9 K
2006-10-11 - 10:15
DerekFeichtinger
gif
cpu20061102.gif
r1
manage
12.6 K
2006-11-02 - 22:25
DerekFeichtinger
gif
dpm_diskfree_cms20061019.gif
r1
manage
9.9 K
2006-10-19 - 10:36
DerekFeichtinger
gif
gridftp20061006.gif
r1
manage
9.7 K
2006-10-06 - 09:49
DerekFeichtinger
gif
gridftp20061011.gif
r1
manage
9.7 K
2006-10-11 - 10:16
DerekFeichtinger
gif
load_fifteen-20061029.gif
r1
manage
10.0 K
2006-10-29 - 13:00
DerekFeichtinger
gif
memory20061029.gif
r1
manage
12.7 K
2006-10-29 - 12:59
DerekFeichtinger
gif
network-wn12-20061101.gif
r1
manage
10.8 K
2006-11-01 - 21:58
DerekFeichtinger
gif
network20061006.gif
r1
manage
12.5 K
2006-10-06 - 09:48
DerekFeichtinger
gif
network20061011.gif
r1
manage
15.5 K
2006-10-11 - 10:16
DerekFeichtinger
gif
network20061102.gif
r1
manage
13.8 K
2006-11-02 - 22:19
DerekFeichtinger
gif
rfio20061102.gif
r1
manage
11.7 K
2006-11-02 - 22:19
DerekFeichtinger
Edit
|
Attach
|
Watch
|
P
rint version
|
H
istory
:
r19
|
r17
<
r16
<
r15
<
r14
|
B
acklinks
|
V
iew topic
|
Raw edit
|
More topic actions...
Topic revision: r15 - 2006-11-16
-
DerekFeichtinger
LCGTier2
Log In
(Topic)
LCGTier2 Web
Create New Topic
Index
Search
Changes
Notifications
Statistics
Preferences
Users
Entry point / Contact
RoadMap
ATLAS Pages
CMS Pages
CMS User Howto
CHIPP CB
Outreach
Technical
Cluster details
Services
Hardware and OS
Tools & Tips
Monitoring
Logs
Maintenances
Meetings
Tests
Issues
Blog
Home
Site map
CmsTier3 web
LCGTier2 web
PhaseC web
Main web
Sandbox web
TWiki web
LCGTier2 Web
Users
Groups
Index
Search
Changes
Notifications
RSS Feed
Statistics
Preferences
P
View
Raw View
Print version
Find backlinks
History
More topic actions
Edit
Raw edit
Attach file or image
Edit topic preference settings
Set new parent
More topic actions
Warning: Can't find topic "".""
Account
Log In
Edit
Attach
Copyright © 2008-2024 by the contributing authors. All material on this collaboration platform is the property of the contributing authors.
Ideas, requests, problems regarding TWiki?
Send feedback



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}