Service Card for NFS
- ha nfs setup:
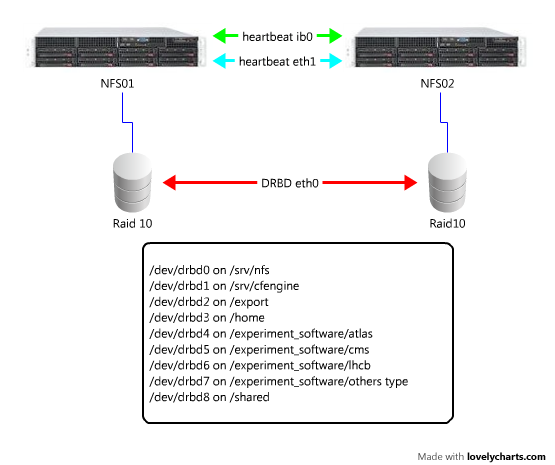
May 30 14:59 [root@nfs02:~]# cat /etc/ha.d/haresources nfs01.lcg.cscs.ch IPaddr::148.187.67.100 \ drbddisk::srv_nfs \ Filesystem::/dev/drbd0::/srv/nfs::ext3 \ drbddisk::export \ Filesystem::/dev/drbd2::/export::ext3 \ drbddisk::home \ Filesystem::/dev/drbd3::/home::ext3 \ drbddisk::atlas \ Filesystem::/dev/drbd4::/experiment_software/atlas::ext3 \ drbddisk::cms \ Filesystem::/dev/drbd5::/experiment_software/cms::ext3 \ drbddisk::lhcb \ Filesystem::/dev/drbd6::/experiment_software/lhcb::ext3 \ drbddisk::other \ Filesystem::/dev/drbd7::/experiment_software/others::ext3 \ drbddisk::shared \ Filesystem::/dev/drbd8::/shared::ext3 nfslock nfs httpd nfs02.lcg.cscs.ch IPaddr::148.187.67.109 \ drbddisk::srv_cfengine \ Filesystem::/dev/drbd1::/srv/cfengine::ext3 cfservd
May 30 15:00 [root@nfs02:~]# cat /etc/ha.d/ha.cf logfacility local0 debugfile /var/log/ha-debug logfile /var/log/ha-log keepalive 2 deadtime 30 initdead 120 udpport 694 # bcast eth0 bcast eth3 auto_failback off # Tell what machines are in the cluster # node nodename ... -- must match uname -n node nfs01.lcg.cscs.ch nfs02.lcg.cscs.ch crm no
mdadm --create /dev/md0 -v --raid-devices=4 --chunk=32 --level=raid10 /dev/sdc /dev/sdd /dev/sde /dev/sdf
pvcreate /dev/md0
vgcreate vgnfs /dev/md0
lvcreate --size 1G --name lv_srv_nfs vgnfs
lvcreate --size 1G --name lv_srv_cfengine vgnfs
lvcreate --size 5G --name lv_export vgnfs
lvcreate --size 100G --name lv_home vgnfs
lvcreate --size 500G --name lv_atlas vgnfs
lvcreate --size 300G --name lv_cms vgnfs
lvcreate --size 5G --name drbd_meta_disk vgnfs
lvcreate --size 200G --name lv_lhcb vgnfs
lvcreate --size 1G --name lv_other_vo vgnfs
lvcreate --size 20G --name lv_shared vgnfs
rpm -Uvh http://download.fedora.redhat.com/pub/epel/5/x86_64/epel-release-5-4.noarch.rpm
yum --enablerepo=epel -y install heartbeat.x86_64
modprobe drbd
chkconfig nfs off
drbdadm create-md srv_nfs
echo yes | drbdadm create-md srv_cfengine
echo yes | drbdadm create-md export
echo yes | drbdadm create-md home
echo yes | drbdadm create-md atlas
echo yes | drbdadm create-md cms
echo yes | drbdadm create-md lhcb
echo yes | drbdadm create-md other
echo yes | drbdadm create-md shared
#drbdadm up all
#service drbd status
mkdir /export
mkdir -p /srv/cfengine
mkdir -p /srv/nfs
mkdir -p /experiment_software/{atlas,cms,lhcb,others}
mkdir -p /shared
NAS appliance
Phoenix has access to part to an EMC NAS appliance installed at CSCS. Currently the quota available for all mount points is ~100TB and consists of 6 heads with several 10GbE links towards the cluster. The following filesystems are exported from this appliance:-
/ifs/LCG/backupis intended to replace the old backup system on the shared fs of/project -
/ifs/LCG/cmholds the RPM repositories and all the configuration management software required to make Phoenix run -
/ifs/LCG/experiment_softwareis intended to be used as a central point where VOs will put their software. Currently only ATLAS requires minimal space here. -
/ifs/LCG/homethis is the home of all users that have access to Phoenix. -
/ifs/LCG/sharedSome important subdirectories are stored here (such asapelaccounting,exp_soft_arc,slurm,gridmapdir, etc.) -
/ifs/LCG/syslogWhere all logs are stored. -
/ifs/LCG/vmThis space holds the VMs that form the preproduction cluster.
| ServiceCardForm | |
|---|---|
| Service name | nfs |
| Machines this service is installed in | nfs[01-02],nas |
| Is Grid service | No |
| Depends on the following services | |
| Expert | Miguel Gila |
| CM | CfEngine |
| Provisioning | none |


Topic revision: r4 - 2014-11-25 - MiguelGila

{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback