CMS SC4 Site log for PHOENIX cluster
June-July 2006:- 31. 5. 2006 srmcp problems, FTS request
- 4.-5. 6. 2006 SE overload
- 6.-7. 6. 2006 SE overload + first attempts to fix it, CMSSW RFIO timeout problem,
- 8. 6. 2006 stopped LoadTest exports (currently only way to reduce SE overload)
- 9. 6. 2006 CE overload due to many blocked job slots
- 16. 6. 2006 High job success rates, but still need to restrict PhEDEx LoadTests
- 21. 6. 2006 SC4 Technical Meeting, cannot get new test sample due to limited disk space
- 22-26. 6. 2006 upgrade to glite3.0
- 30. 6. 2006 stuck jobs due to defect RB and a design flaw in the job bootstrapper, huge number of JobRobot jobs
- 2. 8. 2006 STATUS summary (and DPM / VOMS roles issue)
31. 5. 2006 srmcp problems, FTS request
Lots of intermittent problems of all sorts with the PhEDEx LoadTests and srmcp. The problems are notoriously difficult to debug and often of an intermittent nature (started writing some scripts, but I do not want to go into details here) Followed Lassi's suggestion to try out the FTS backend and asked for additional FTS channels at the GGUS portal (we currently have only to/from FZK, Link to the GGUS Ticket
4.-5. 6. 2006 SE overload
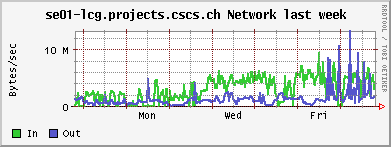
The PhEDEx Load tests (with srmcp backend) create so much load on our single file server, that it affects running jobs accessing data sets using rfio/POSIX protocol. Several CMS integration test jobs had timeouted the previous day. As shown by the Ganglia CPU graph, the SE's CPU is most of the time waiting for I/O. A test involving a rfcp of a datafile to the UI under this load yielded only an effective download I/O rate of about 90KB/s! Every srmcp uses up to 10 gridftp streams (the default). I tried to reduce the load by setting the streams/transfer to 2, which alleviated the situation only slightly. The maximal observed data rate from/to the SE was generated by the LoadTests and amounted to ~30 MB/s. I stopped the LoadTests around 24h to allow the CMS integration test jobs to work undisturbed. I/O by these jobs seemed rather low: < 100 KB/s per job. Since the CPU load on a node running one of these jobs is close to 100%, it seems that this low rate is not due to any performance issues of the SE, but that the job is CPU limited. Restarted the LoadTests at noon. It is to be expected that more I/O demanding analysis jobs will run into trouble with our current storage solution (however, the first significant upgrade to the cluster, which is planned for this year, will repair these deficiencies). The JobRobot analysis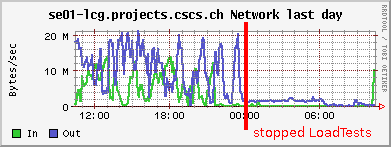

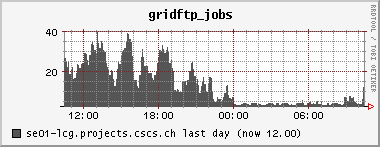
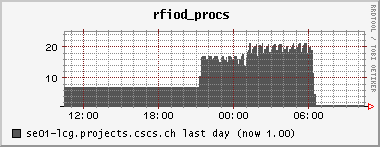
6.-7. 6. 2006 SE overload + first attempts to fix it, CMSSW RFIO timeout problem,
Again, three jobs got stuck, probably because of SE overload (lots of walltime, no cpu time, SE mostly in CPU WAIT state). There were almost 200 gridftp processes running wild on the SE at one time today. I used the -jobs switch of the PhEDEx LoadTest download agent to reduce the number of parallel downloads, and set it to 2 (default was 5). How can I control the number of parallel downloads from our center to the other centers? They are operated by the other centers.
Use of tracked parameters for the message service is deprecated.
The .cfg file should be modified to make this untracked.
SysError in <TRFIOFile::ReadBuffer>: error reading from
file /dpm/projects.cscs.ch/home/cms/trivcat/store/preprod/2006/05/05/PreProdR3Minbias/0000/
920AFCA1-22DA-DA11-9151-003048723767.root (Timed out)
Error in <TRFIOFile::ReadBuffer>: error reading all requested bytes from
file /dpm/projects.cscs.ch/home/cms/trivcat/store/preprod/2006/05/05/PreProdR3Minbias/0000/920A
FCA1-22DA-DA11-9151-003048723767.root, got 19403 of 17981
*** Break *** segmentation violation
I filed this bug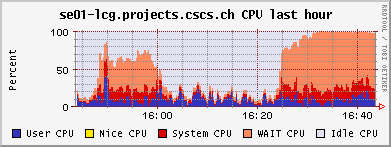

8. 6. 2006 stopped LoadTest exports (currently only way to reduce SE overload)
Decided to only run the LoadTests download agent, but not the export agents, since we have no control over exports (except completely denying them). There ought to be a way for a site to control I/O bandwidth for requests from other sites. Even though our current SE solution is surely inadequate (just 1 big fileserver), the principal problems are in the middleware. If too many jobs try to access the same disks simultaneously, the disks get extremely inefficient, even though they could easily provide the I/O with a more sequential access pattern. Having on the order of 100 parallel gridftps for the WAN transfers + all the accesses from the WNs is just getting too much. Why must a site download 23 files in parallel (as happened yesterday), instead of using a more sequential approach? The parallelism should enter at the level of parallel streams, and over the number of these both sites should have some control, e.g. by setting an upper limit.9. 6. 2006 CE overload due to many blocked job slots
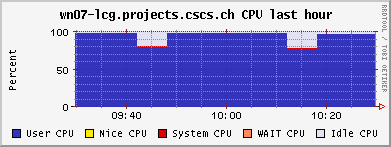
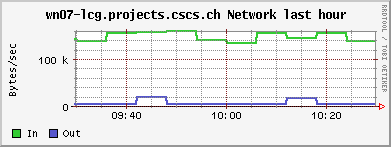
The JobRobot throws jobs at us faster than we can handle them at the moment. The nodes are today still working on some files from 3 days ago. One recurring problem are jobs from other users/experiments that end up blocking the queues, because they are waiting for some I/O from off-site, leaving the CPU completely idle (similar in effect to the cmsRun jobs failing and hanging because of RFIO timeout, q.v. yesterday). I have now scripts which detect them, but the removal of the jobs is a manual process, i.e. notifying the sysadmin, who then has to investigate to whom the jobs belong, etc.......
Thinking of reconfiguring the queues... Why do we have to reserve whole CPUs for dteam and the experiments' software managers? We could assign an extra virtual slot for these nodes. Then both CPU's of these nodes would be continually busy, and if then a third job hets started for these special users, the node will be a bit inefficient. But this is still better than to almost continually waste 5 CPUs.
It was clear from the start, that our cluster is too weak in its current form, and the upgrade will still take several months. Still, it is
good to build up experience with the technology, especially as it helps with planning the layout of the upgrade.
Some observations regarding the current JobRobot jobs: Two jobs were running on this node. Average job's running time is 30 min.
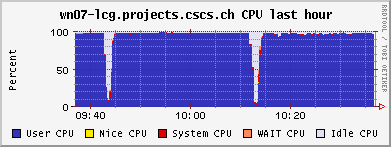
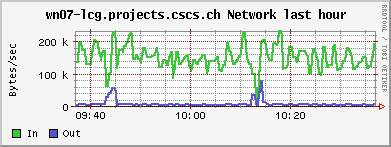 Around 20h all JobRobots disappeared from our CE, so it seems that Oliver Gutsche has taken us out of the Robot for now.
Around 20h all JobRobots disappeared from our CE, so it seems that Oliver Gutsche has taken us out of the Robot for now.
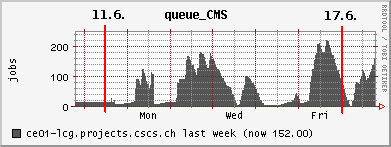
16. 6. 2006 High job success rates, but still need to restrict PhEDEx LoadTests
Spent several days at the T2 workshop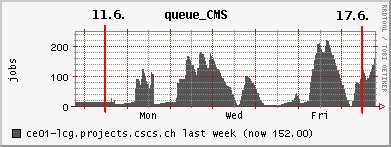
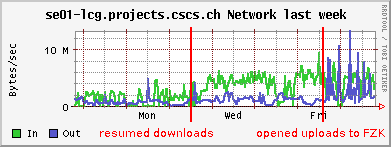 20. 6. 2006 Hypernews message
20. 6. 2006 Hypernews message21. 6. 2006 SC4 Technical Meeting, cannot get new test sample due to limited disk space
Link22-26. 6. 2006 upgrade to glite3.0
Upgrade was announced for 22-23 June. Due to an RGMA problem the cluster only was ready again on Mo evening, 26 June.30. 6. 2006 stuck jobs due to defect RB and a design flaw in the job bootstrapper, huge number of JobRobot jobs
Found a number of stuck jobs. As usual they were waiting for I/O from the WAN. In this case the jobs were in the bootstrap phase and tried to retrieve their input box from the egee-rb-04.cnaf.infn.it resource broker. The broker was not able to serve the files and the jobs kept hanging forever in the globus-url-copy. This seems a design flaw and there should be a timeout after which the job gives up and releases the resource (notified Andrea Sciaba, also see this hn thread2. 8. 2006 STATUS summary (and DPM / VOMS roles issue)
PhEDEx: Still running with srmcp (had done some manual FTS tests with FZK, but the priority in integration was to get T0-T1 transfers working first). Good downloads from FNAL, IN2P3. Bad results for FZK and RAL. Need to start investigating again. Downloads from our site are limited to T1_FZK_Load and T1_FZK_Buffer to prevent excessive traffic. JobRobot: Often jobs get killed, because the site cannot handle them in time. This is due to regular jobs running for long times on the same resources. I currently do not prioritize JobRobot jobs any more. Production: Even though CMSSW_0_8_1 is installed and is working (also fixed the DPM/rfio issue that had popped up again), we are blocked by another DPM problem. The new VOMS based proxy certificates allow users to assume authorization roles. These roles get directly mapped to a DPM user group ("cms/Role=production" in this case). But a group dedicated pool in DPM only allows members of the dedicated group to write into it, and this is the way DPM gets deployed at multi-VO SE's - one VO per pool. So, even if DPM ACLs are used to allow another group write access to a directory of the pool, this other group is prevented from creating files, because of the disk quota, which seems to be zero for all groups except the principal one. Still, the production group is allowed to delete files, but this is not much use. Jean-Philipe Baud and Sophie Lemaitre from LCG wrote in reply to my requests that it may well take until end of the year, before work to resolve these issues is done (q.v. also this hypernews thread

| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
cpu0604.gif | r1 | manage | 13.2 K | 2006-06-05 - 14:14 | DerekFeichtinger | |
| |
cpu0607.gif | r1 | manage | 12.4 K | 2006-06-07 - 14:38 | DerekFeichtinger | |
| |
gridftp0604.gif | r1 | manage | 10.7 K | 2006-06-05 - 14:15 | DerekFeichtinger | |
| |
network0604.gif | r1 | manage | 5.8 K | 2006-06-05 - 14:15 | DerekFeichtinger | |
| |
network0607.gif | r1 | manage | 12.5 K | 2006-06-07 - 14:39 | DerekFeichtinger | |
| |
network0617.gif | r2 r1 | manage | 5.4 K | 2006-06-21 - 10:14 | DerekFeichtinger | |
| |
queuecms0617.gif | r2 r1 | manage | 4.1 K | 2006-06-17 - 17:03 | DerekFeichtinger | |
| |
rfio0604.gif | r1 | manage | 10.8 K | 2006-06-05 - 14:16 | DerekFeichtinger | |
| |
wn07-cpu0609.gif | r2 r1 | manage | 11.1 K | 2006-06-09 - 08:32 | DerekFeichtinger | |
| |
wn07-network0609.gif | r2 r1 | manage | 12.4 K | 2006-06-09 - 08:31 | DerekFeichtinger |
Topic revision: r23 - 2007-02-12 - DerekFeichtinger

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback