Service Card for GPFS2
This is the service page for the GPFS2 scratch filesystem.Operations
Server tools
- PDSH commands can be launched from
phoenix1.lcg.cscs.chorphoenix2.lcg.cscs.chusing the groupGPFS2$ pdsh -l root -g GPFS2 hostname 2>/dev/null |sort itchy01: itchy01.lcg.cscs.ch itchy02: itchy02.lcg.cscs.ch itchy03: itchy03.lcg.cscs.ch itchy04: itchy04 scratchy01: scratchy01.lcg.cscs.ch scratchy02: scratchy02.lcg.cscs.ch scratchy03: scratchy03.lcg.cscs.ch scratchy04: scratchy04.lcg.cscs.ch
- Also, as on any GPFS system, there is the
mmdshtool:# mmdsh -N all hostname 2>/dev/null |head arc02.10: arc02.lcg.cscs.ch scratchy02-a: scratchy02.lcg.cscs.ch wn121.10: wn121.lcg.cscs.ch wn127.10: wn127.lcg.cscs.ch wn16.10: wn16.lcg.cscs.ch wn30.10: wn30.lcg.cscs.ch wn112.10: wn112.lcg.cscs.ch wn123.10: wn123.lcg.cscs.ch wn103.10: wn103.lcg.cscs.ch wn104.10: wn104.lcg.cscs.ch
Restore down disks/NSDs
If we are in a situation in which NSDs are down (metadata in the example below), we need to follow some steps in order to restore the system:# mmlsdisk phoenix_scratch -L |grep down itchy01_sda nsd 512 10 Yes No ready down 13 system itchy01_sdb nsd 512 10 Yes No ready down 14 system itchy01_sdc nsd 512 10 Yes No ready down 15 systemRestoring NSDs:
# mmchdisk phoenix_scratch start -d "itchy01_sda;itchy01_sdb;itchy01_sdc" mmnsddiscover: Attempting to rediscover the disks. This may take a while ... mmnsddiscover: Finished. itchy01.lcg.cscs.ch: Rediscovered nsd server access to itchy01_sda. itchy01.lcg.cscs.ch: Rediscovered nsd server access to itchy01_sdb. itchy01.lcg.cscs.ch: Rediscovered nsd server access to itchy01_sdc. Scanning file system metadata, phase 1 ... 1 % complete on Thu Oct 2 15:38:14 2014 [...] Scan completed successfully. Scanning user file metadata ... 3.11 % complete on Thu Oct 2 16:04:27 2014 ( 4338880 inodes with total 20274 MB data processed) [...] 43.84 % complete on Thu Oct 2 16:09:27 2014 ( 70666560 inodes with total 286141 MB data processed) 46.62 % complete on Thu Oct 2 16:09:47 2014 ( 75303744 inodes with total 304255 MB data processed) 49.43 % complete on Thu Oct 2 16:10:07 2014 ( 80003904 inodes with total 322615 MB data processed) 100.00 % complete on Thu Oct 2 16:10:12 2014 Scan completed successfully.
Replace a broken disk
If one of the disks not in a RAID volume (SSDs for metadata onitchy01 and itchy02 ) fails, you will find it as down:
itchy02_sda nsd 512 11 Yes No ready down systemThe procedure to replace it is, once the physical has been replaced do this:
- Delete the disk:
# mmdeldisk phoenix_scratch itchy02_sda -p Verifying file system configuration information ... Deleting disks ... Checking Allocation Map for storage pool system Checking Allocation Map for storage pool data 50 % complete on Fri Jan 23 16:02:18 2015 100 % complete on Fri Jan 23 16:02:22 2015 Scanning file system metadata, phase 1 ... 1 % complete on Fri Jan 23 16:02:27 2015 2 % complete on Fri Jan 23 16:03:31 2015 [...]
- Delete the NSD just emptied:
# mmdelnsd itchy02_sda mmdelnsd: Processing disk itchy02_sda mmdelnsd: Unable to find disk with NSD volume id 94BB402353D12C6E. mmdelnsd: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.
- Create the nsd file on the new device:
# cat nsd.23.01.15.conf %nsd: nsd=itchy02_sda device=/dev/sde failureGroup=11 usage=metadataOnly pool=system servers=itchy02
- Create NSD file:
# mmcrnsd -F ./nsd.23.01.15.conf
- Add the disk back with rebalance enabled:
# mmadddisk phoenix_scratch -F nsd.23.01.15.conf -r The following disks of phoenix_scratch will be formatted on node scratchy01.lcg.cscs.ch: itchy02_sda: size 195360984 KB Extending Allocation Map [...]
Client tools
GPFS Repositories
There are two GPFS RPM repositories within Phoenix:- gpfs-base
 The base gpfs-3.5 packages are located here (http://foreman.lcg.cscs.ch/gpfs/$releasever/base/)
The base gpfs-3.5 packages are located here (http://foreman.lcg.cscs.ch/gpfs/$releasever/base/)
- gpfs-updates All updates of GPFS go here (http://foreman.lcg.cscs.ch/gpfs/$releasever/updates/)
Client mountpoints and symlinks
GPFS2 mounts on/gpfs2 and contains two filesets: gridhome and scratch
On WNs, CREAM-CEs and ARC-CEs, the following structure needs to exist: < -
/home/nordugrid-atlas --> /gpfs2/gridhome/nordugrid-atlas-slurm -
/home/nordugrid-atlas-slurm --> /gpfs2/gridhome/nordugrid-atlas-slurm -
/home/wlcg --> /gpfs2/gridhome/wlcg -
/tmpdir_slurm --> /gpfs2/scratch/tmpdir_slurm
Cleanup old CREAM-CE jobs
On a WN, use the script:https://git.cscs.ch/misc/slurm_scripts/blob/master/clean_finished_jobs
This will scan the filesystem and cleanup all finished but stored CREAM-CE jobs.
Client update
- Clean the metadata information about repositories
yum clean all
- Update the GPFS packages:
yum update gpfs.docs gpfs.msg.en_US gpfs.docs gpfs.base
- Install the GPFS kernel modules for the new version of GPFS and the running kernel:
yum install gpfs.gplbin-$(uname -r)
Client installation
- First you need to install the initial release of the base package.
yum localinstall http://phoenix1.lcg.cscs.ch:81/gpfs/el6/base/gpfs.base-3.5.0-0.x86_64.rpm
- Now lets install the other packages we need (these are fetched from the gpfs-updates repo):
yum install gpfs.docs gpfs.msg.en_US gpfs.docs gpfs.base
- And last, but not least, we need to install the kernel module
yum install gpfs.gplbin-$(uname -r)
Refresh a reinstalled client
- Copy /var/mmfs/gen/mmsdrfs from other node (any) to the reinstalled system.
[root@wn11:/] scp wn45:/var/mmfs/gen/mmsdrfs /var/mmfs/gen/
- Run mmrefresh -f on the reinstalled node.
[root@wn11:gen]# mmrefresh -f [root@wn11:gen]# mmgetstate Node number Node name GPFS state ------------------------------------------ 11 wn11 down [root@wn11:gen]# mmstartup
Compiling the GPFS kernel modules.
In order to compile the module for the current kernel and GPFS version, we need to install the client and then build and install thegpfs.gplbin-KERNELVERS package.
- Build the package on the node with the last version of GPFS installed and the kernel as well
cd /usr/lpp/mmfs/src make LINUX_DISTRIBUTION=REDHAT_AS_LINUX Autoconfig make World make rpm #rpm -ivh /root/rpmbuild/RPMS/x86_64/gpfs.gplbin-*.rpm #modprobe mmfs26
- Make this available by yum for future installs. Note this was built with the GPFS-3.5.0-10 packages.
scp /root/rpmbuild/RPMS/x86_64/gpfs.gplbin-*.rpm phoenix1:/cm/www/html/gpfs/el6/updates/
- Update the repo on
phoenix1:cd /cm/www/html/gpfs/el6/updates/ createrepo --update -p .
- Install the client using yum, as explained before.
yum clean all yum install gpfs.gplbin-$(uname -r)
Start/stop procedures
Fromitchy01 or itchy02 do the following:
- Start:
# mmgetstate -a # mmstartup -a
- Stop:
# mmshutdown -a </verbatim> Note that this will shutdown GPFS on all nodes of the cluster, including WNs.
Checking logs
GPFS logs can be found under the following directory, note the file/var/adm/ras/mmfs.log.latest is a symlink and has been seen to point to the wrong file
/var/adm/ras/Events related to the kernel module will appear in syslog typically
/var/log/messages
Set up
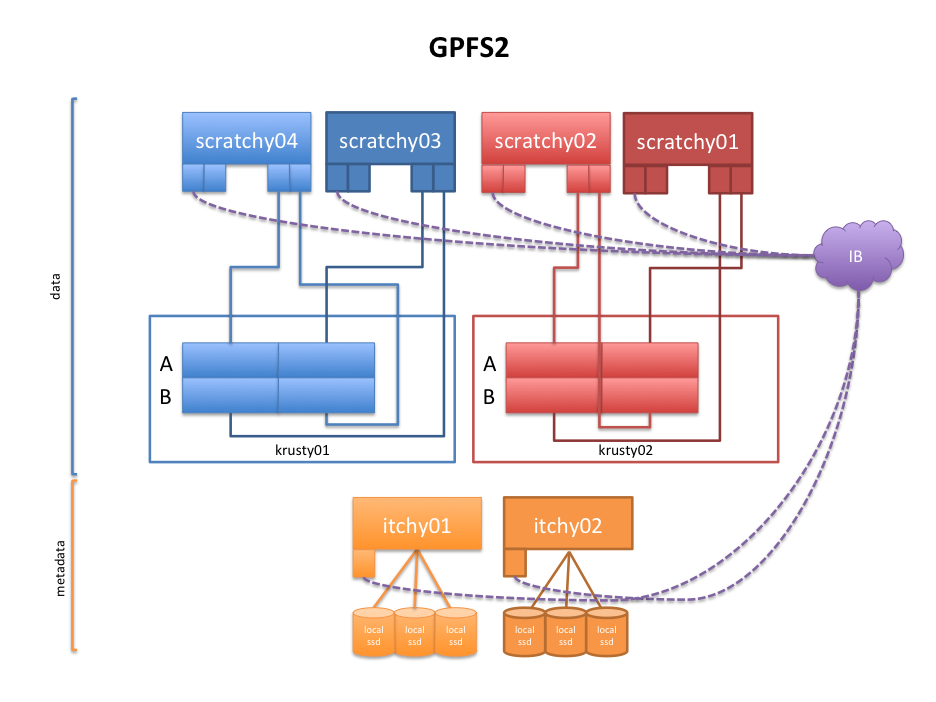
Storage
The storage of this service consists on 2 NetApp E5560-BASE-R6 with 60 10k SAS disks each. The name enclosures are calledkrusty01 and krusty02
The software SMclient (SanTricity) required to manage these storage units is, at minimum, version 11.10. It is installed on berninasmw
On each enclosure there are configured 6 Volume Groups (RAID6) with one Volume on each Volume Group. No hot spares are defined. -
krusty01_array[0-5]- each volume provides ~ 6TB. Total of ~36 TB. -
krusty02_array[0-5]- each volume provides ~ 6TB. Total of ~36 TB.
krusty01):
create hostGroup userLabel="scratchy04-03"; create host userLabel="scratchy04" hostType=6 hostGroup="scratchy04-03"; create host userLabel="scratchy03" hostType=6 hostGroup="scratchy04-03"; create hostPort host="scratchy03" userLabel="scratchy03_card1_port2" identifier="0100e45529e58000f4521403007f0b42" interfaceType=IB; create hostPort host="scratchy03" userLabel="scratchy03_card1_port1" identifier="0200a85129e58000f4521403007f0b41" interfaceType=IB; create hostPort host="scratchy04" userLabel="scratchy04_card1_port1" identifier="0200e45529e58000f4521403007f1091" interfaceType=IB; create hostPort host="scratchy04" userLabel="scratchy04_card1_port2" identifier="0100a85129e58000f4521403007f1092" interfaceType=IB;These host port identifiers (as seen by the Storage Arrays) can be easily retrieved using SMclient selecting from the Enterprise Management one of the Storage Arrays and selecting in its specific GUI:
Host Mappings -> View Unassociated Host Port IdentifiersThe identifier for each machine and card can then be compared running the following on the server:
$ ibstatus |grep 'default gid' -B 1 Infiniband device 'mlx4_0' port 1 status: default gid: fe80:0000:0000:0000:f452:1403:007f:07e1 -- Infiniband device 'mlx4_0' port 2 status: default gid: fe80:0000:0000:0000:f452:1403:007f:07e2 -- Infiniband device 'mlx4_1' port 1 status: default gid: fe80:0000:0000:0000:f452:1403:007f:07f1 -- Infiniband device 'mlx4_1' port 2 status: default gid: fe80:0000:0000:0000:f452:1403:007f:07f2You can easily match these numbers with the configuration shown in
SMclient as described above ( Unassociated Identifiers).
From the server you can examine which enclosure you are connected to with the following. Note you must specify /dev/infiniband/umad2 or /dev/infiniband/umad3 as the device. This is because /dev/infiniband/umad0 is used by default, in our case this is not connected to any SRP devices this causes ibsrpdm to usefully hang rather than aborting.
ibsrpdm -d /dev/infiniband/umad2
IO Unit Info:
port LID: 0004
port GID: fe800000000000000080e52951a80002
change ID: 0003
max controllers: 0x10
controller[ 1]
GUID: 0080e52951a80003
vendor ID: 0002c9
device ID: 00673c
IO class : 0100
ID: NetApp RAID Controller SRP Driver 20120080e52951a8
service entries: 1
service[ 0]: 20120080e52951a8 / SRP.T10:22120080E52951A8
Servers
There are 8 IBM x3650 M4 servers in GPFS2, 4 for metadata (with SSDs) and 4 for data.- Metadata servers are
itchy01,itchy02,itchy03anditchy04with 2x disks in RAID-1 for OS, 3x SSD SAS disks (without RAID) for metadata and 4x IB FDR ports. - Data servers are = scratchy0[1-4]= with OS on 10k RPM SAS disks and 4 IB FDR ports.
- Installed with
eth0due to the particularities of Razor and Puppet. - OS is Red Hat Enterprise Linux 6
- IB stack from Red Hat.
- In order to see the volumes configured in the storage enclosures, the following needs to be taken into account:
- SRP module on the
rdma.confhas to be enabled# Load SRP module SRP_LOAD=yes
- The following RPMs need to be present on the system:
sudo yum install opensm srptools ddn-ibsrp device-mapper-multipath sg3_utils
- And services
ddn-ibsrpandmultipathdneed to start on boot. The former starts thesrdpdaemon and the latter starts the IB Subnet Manageropensmon each of the IB devices connected to the storage system
- SRP module on the
- Multipath configuration is as follows
devices { device { vendor "NETAPP" product "INF-01-00" hardware_handler "1 rdac" path_checker rdac failback 5 path_grouping_policy group_by_prio #prio_callout "/sbin/mpath_prio_tpc /dev/%n" prio rdac } } blacklist { device { product "ServeRAID M5110e" } }Be aware that each pair of systems see all the LUNs!
GPFS filesystem creation
[root@itchy01 ~]# cat rule-metadata.out RULE 'default' SET POOL 'data' [root@itchy01 ~]# cat /root/nsd.conf %nsd: nsd=krusty01_array0 device=/dev/mapper/krusty01_array0 failureGroup=1 usage=dataOnly pool=data servers=scratchy03,scratchy04 %nsd: nsd=krusty01_array1 device=/dev/mapper/krusty01_array1 failureGroup=1 usage=dataOnly pool=data servers=scratchy04,scratchy03 %nsd: nsd=krusty01_array2 device=/dev/mapper/krusty01_array2 failureGroup=1 usage=dataOnly pool=data servers=scratchy03,scratchy04 %nsd: nsd=krusty01_array3 device=/dev/mapper/krusty01_array3 failureGroup=1 usage=dataOnly pool=data servers=scratchy04,scratchy03 %nsd: nsd=krusty01_array4 device=/dev/mapper/krusty01_array4 failureGroup=1 usage=dataOnly pool=data servers=scratchy03,scratchy04 %nsd: nsd=krusty01_array5 device=/dev/mapper/krusty01_array5 failureGroup=1 usage=dataOnly pool=data servers=scratchy04,scratchy03 %nsd: nsd=krusty02_array0 device=/dev/mapper/krusty02_array0 failureGroup=2 usage=dataOnly pool=data servers=scratchy02,scratchy01 %nsd: nsd=krusty02_array1 device=/dev/mapper/krusty02_array1 failureGroup=2 usage=dataOnly pool=data servers=scratchy01,scratchy02 %nsd: nsd=krusty02_array2 device=/dev/mapper/krusty02_array2 failureGroup=2 usage=dataOnly pool=data servers=scratchy02,scratchy01 %nsd: nsd=krusty02_array3 device=/dev/mapper/krusty02_array3 failureGroup=2 usage=dataOnly pool=data servers=scratchy01,scratchy02 %nsd: nsd=krusty02_array4 device=/dev/mapper/krusty02_array4 failureGroup=2 usage=dataOnly pool=data servers=scratchy02,scratchy01 %nsd: nsd=krusty02_array5 device=/dev/mapper/krusty02_array5 failureGroup=2 usage=dataOnly pool=data servers=scratchy01,scratchy02 %nsd: nsd=itchy01_sda device=/dev/sda failureGroup=10 usage=metadataOnly pool=system servers=itchy01 %nsd: nsd=itchy01_sdb device=/dev/sdb failureGroup=10 usage=metadataOnly pool=system servers=itchy01 %nsd: nsd=itchy01_sdc device=/dev/sdc failureGroup=10 usage=metadataOnly pool=system servers=itchy01 %nsd: nsd=itchy02_sda device=/dev/sda failureGroup=11 usage=metadataOnly pool=system servers=itchy02 %nsd: nsd=itchy02_sdb device=/dev/sdb failureGroup=11 usage=metadataOnly pool=system servers=itchy02 %nsd: nsd=itchy02_sdc device=/dev/sdc failureGroup=11 usage=metadataOnly pool=system servers=itchy02 %nsd: nsd=itchy03_sdb device=/dev/sdb failureGroup=10 usage=metadataOnly pool=system servers=itchy03 %nsd: nsd=itchy03_sdc device=/dev/sdc failureGroup=10 usage=metadataOnly pool=system servers=itchy03 %nsd: nsd=itchy03_sdd device=/dev/sdd failureGroup=10 usage=metadataOnly pool=system servers=itchy03 %nsd: nsd=itchy04_sdb device=/dev/sdb failureGroup=11 usage=metadataOnly pool=system servers=itchy04 %nsd: nsd=itchy04_sdc device=/dev/sdc failureGroup=11 usage=metadataOnly pool=system servers=itchy04 %nsd: nsd=itchy04_sdd device=/dev/sdd failureGroup=11 usage=metadataOnly pool=system servers=itchy04 [root@itchy01 ~]# mmdelfs phoenix_scratch -p [root@itchy01 ~]# mmcrfs phoenix_scratch -F /root/nsd.conf -v no -A yes -B 1M -i 4k -M 2 -m 2 -R 1 -r 1 -n 200 -Q yes --metadata-block-size 128K -T /gpfs2 --inode-limit 1000000:1000000 [root@itchy01 ~]# mmchpolicy phoenix_scratch rule-metadata.out [root@itchy01 ~]# mmcrfileset phoenix_scratch gridhome --inode-space new --inode-limit 50000000:50000000 [root@itchy01 ~]# mmcrfileset phoenix_scratch scratch --inode-space new --inode-limit 330000000:330000000 [root@itchy01 ~]# mmmount phoenix_scratch [root@itchy01 ~]# mmlinkfileset phoenix_scratch gridhome -J /gpfs2/gridhome [root@itchy01 ~]# mmlinkfileset phoenix_scratch scratch -J /gpfs2/scratch [root@itchy01 ~]# export QUOTA_scratch="330000000" [root@itchy01 ~]# export QUOTA_gridhome="45000000" [root@itchy01 ~]# mmsetquota -j gridhome --inode_hardquota ${QUOTA_gridhome} --inode_softquota ${QUOTA_gridhome} phoenix_scratch [root@itchy01 ~]# mmsetquota -j scratch --inode_hardquota ${QUOTA_scratch} --inode_softquota ${QUOTA_scratch} phoenix_scratch [root@itchy01 ~]# mmauth grant gpfs.lcg.cscs.ch -f all [root@itchy01 ~]# mmchnode --admin-interface=itchy01-a -N itchy01.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=itchy02-a -N itchy02.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=scratchy01-a -N scratchy01.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=scratchy02-a -N scratchy02.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=scratchy03-a -N scratchy03.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=scratchy04-a -N scratchy04.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=itchy03.mngt -N itchy03.lcg.cscs.ch [root@itchy01 ~]# mmchnode --admin-interface=itchy04.mngt -N itchy04.lcg.cscs.ch [root@itchy01 ~]# mmchconfig pagepool=2G -i [root@itchy01 ~]# mmchconfig pagepool=32G -i -N itchy01.lcg.cscs.ch,itchy02.lcg.cscs.ch,scratchy01.lcg.cscs.ch,scratchy02.lcg.cscs.ch,scratchy03.lcg.cscs.ch,scratchy04.lcg.cscs.ch [root@itchy01 ~]# mmchconfig pagepool=64G -i -N itchy03.lcg.cscs.ch,itchy04.lcg.cscs.ch [root@itchy01 ~]# mmchconfig nsdMaxWorkerThreads=36 [root@itchy01 ~]# mmchconfig minMissedPingTimeout=60 [root@itchy01 ~]# mmchconfig sendTimeout=60 [root@itchy01 ~]# mmchnode --manager --nonquorum -N itchy02.lcg.cscs.ch,scratchy02.lcg.cscs.ch,scratchy04.lcg.cscs.ch,itchy03.lcg.cscs.ch,itchy04.lcg.cscs.ch [root@itchy01 ~]# mmchnode --manager --quorum -N itchy01.lcg.cscs.ch,scratchy01.lcg.cscs.ch,scratchy03.lcg.cscs.ch [root@wn65:~]# mmremotecluster update phoenix_scratch.lcg.cscs.ch -n 10.10.64.34,10.10.64.35 [root@itchy01 ~]# mmchconfig subnets=148.187.64.0/gpfs.lcg.cscs.ch [root@itchy01 ~]# mmstartup -a [root@wn18:~]# mmmount phoenix_scratch [root@wn18:~]# /opt/cscs/sbin/clean_grid_accounts.bash [root@wn18:~]# cd /gpfs2 [root@wn18:~]# mkdir -p gridhome/nordugrid-atlas-slurm [root@wn18:~]# mkdir -p gridhome/wlcg [root@wn18:~]# mkdir -p scratch/tmpdir_slurm [root@wn18:~]# mkdir -p scratch/tmpdir_slurm/arc_cache [root@wn18:~]# mkdir -p scratch/tmpdir_slurm/arc_sessiondir [root@wn18:~]# mkdir -p scratch/tmpdir_slurm/{cream01.lcg.cscs.ch,cream02.lcg.cscs.ch,cream03.lcg.cscs.ch,cream04.lcg.cscs.ch} [root@wn18:~]# chmod 1777 /gpfs2/scratch/ [root@wn18:~]# chmod 1777 /gpfs2/gridhome [root@wn18:~]# chmod 1777 scratch/tmpdir_slurm [root@wn18:~]# chmod 1777 scratch/tmpdir_slurm/cream*
GPFS configuration
At the moment of writting these lines, the GPFS cluster configuration is seen below. Note that there are no WNs or other grid nodes here; this is because until we switch over to this GPFS2 filesystem, all the nodes belong to the old GPFS cluster and can only see this new filesystem via remote mounting.# mmlscluster |grep -v -E 'wn|arc|cream' GPFS cluster information ======================== GPFS cluster name: phoenix_scratch.lcg.cscs.ch GPFS cluster id: 7846265090610531627 GPFS UID domain: lcg.cscs.ch Remote shell command: /usr/bin/ssh Remote file copy command: /usr/bin/scp GPFS cluster configuration servers: ----------------------------------- Primary server: itchy01-a Secondary server: itchy02-a Node Daemon node name IP address Admin node name Designation ---------------------------------------------------------------------------- 1 itchy01.lcg.cscs.ch 148.187.64.34 itchy01-a quorum-manager 2 itchy02.lcg.cscs.ch 148.187.64.35 itchy02-a manager 3 scratchy01.lcg.cscs.ch 148.187.64.30 scratchy01-a quorum-manager 4 scratchy02.lcg.cscs.ch 148.187.64.31 scratchy02-a manager 5 scratchy03.lcg.cscs.ch 148.187.64.32 scratchy03-a quorum-manager 6 scratchy04.lcg.cscs.ch 148.187.64.33 scratchy04-a manager 126 itchy03.lcg.cscs.ch 148.187.64.36 itchy03.mngt manager 127 itchy04.lcg.cscs.ch 148.187.64.37 itchy04.mngt manager
Filesystems and filesets
There is ONE filesystemphoenix_scratch and two filesets gridhome and scratch. Each fileset has different number of inodes and quota limits, although now only inode numbers are controlled using quotas. In the end, a fileset is a folder within the filesystem with specific parameters.
# mmlsfileset phoenix_scratch -L
Filesets in file system 'phoenix_scratch':
Name Id RootInode ParentId Created InodeSpace MaxInodes AllocInodes Comment
root 0 3 -- Mon Oct 6 16:40:47 2014 0 1000128 1000128 root fileset
gridhome 1 1048579 0 Mon Oct 6 16:41:18 2014 1 50000000 50000000
scratch 2 67108867 0 Thu Apr 16 08:41:07 2015 2 330000000 330000000
# mmrepquota -j phoenix_scratch
Block Limits | File Limits
Name type KB quota limit in_doubt grace | files quota limit in_doubt grace
root FILESET 23647936 0 0 0 none | 21 0 0 0 none
gridhome FILESET 333920 0 0 1589632 none | 234150 45000000 45000000 1481 none
scratch FILESET 1638649024 0 0 28472128 none | 59445715 330000000 330000000 152142 none
Dependencies (other services, mount points, ...)
A number of comments of GPFS have a dependency on the korn shell so ensure ksh is available wherever you run GPFS (client and server). Note this is not listed as a dependency by the GPFS RPMs.Redundancy
The metadata and storage servers are split into their own failure groups.# mmlsdisk /dev/phoenix_scratch disk driver sector failure holds holds storage name type size group metadata data status availability pool ------------ -------- ------ ----------- -------- ----- ------------- ------------ ------------ krusty01_array0 nsd 512 1 No Yes ready up data krusty01_array1 nsd 512 1 No Yes ready up data krusty01_array2 nsd 512 1 No Yes ready up data krusty01_array3 nsd 512 1 No Yes ready up data krusty01_array4 nsd 512 1 No Yes ready up data krusty01_array5 nsd 512 1 No Yes ready up data krusty02_array0 nsd 512 2 No Yes ready up data krusty02_array1 nsd 512 2 No Yes ready up data krusty02_array2 nsd 512 2 No Yes ready up data krusty02_array3 nsd 512 2 No Yes ready up data krusty02_array4 nsd 512 2 No Yes ready up data krusty02_array5 nsd 512 2 No Yes ready up data itchy01_sda nsd 512 10 Yes No ready up system itchy01_sdb nsd 512 10 Yes No ready up system itchy01_sdc nsd 512 10 Yes No ready up system itchy02_sda nsd 512 11 Yes No ready up system itchy02_sdb nsd 512 11 Yes No ready up system itchy02_sdc nsd 512 11 Yes No ready up system itchy03_sdb nsd 512 10 Yes No ready up system itchy03_sdc nsd 512 10 Yes No ready up system itchy03_sdd nsd 512 10 Yes No ready up system itchy04_sdb nsd 512 11 Yes No ready up system itchy04_sdc nsd 512 11 Yes No ready up system itchy04_sdd nsd 512 11 Yes No ready up systemThe default policy of the file system is to have two copies for the GPFS metadata as such we should be able to withstand a failure of two metadata servers on the same failure group.
Installation/configuration
# mmlsfs phoenix_scratch
flag value description
------------------- ------------------------ -----------------------------------
-f 4096 Minimum fragment size in bytes (system pool)
32768 Minimum fragment size in bytes (other pools)
-i 4096 Inode size in bytes
-I 32768 Indirect block size in bytes
-m 2 Default number of metadata replicas
-M 2 Maximum number of metadata replicas
-r 1 Default number of data replicas
-R 1 Maximum number of data replicas
-j cluster Block allocation type
-D nfs4 File locking semantics in effect
-k all ACL semantics in effect
-n 200 Estimated number of nodes that will mount file system
-B 131072 Block size (system pool)
1048576 Block size (other pools)
-Q user;group;fileset Quotas enforced
none Default quotas enabled
--filesetdf No Fileset df enabled?
-V 13.23 (3.5.0.7) File system version
--create-time Mon Oct 6 16:40:57 2014 File system creation time
-u Yes Support for large LUNs?
-z No Is DMAPI enabled?
-L 4194304 Logfile size
-E Yes Exact mtime mount option
-S No Suppress atime mount option
-K whenpossible Strict replica allocation option
--fastea Yes Fast external attributes enabled?
--inode-limit 381000128 Maximum number of inodes in all inode spaces
-P system;data Disk storage pools in file system
-d krusty01_array0;krusty01_array1;krusty01_array2;krusty01_array3;krusty01_array4;krusty01_array5;krusty02_array0;krusty02_array1;krusty02_array2;krusty02_array3;krusty02_array4;
-d krusty02_array5;itchy01_sda;itchy01_sdb;itchy01_sdc;itchy02_sda;itchy02_sdb;itchy02_sdc;itchy03_sdb;itchy03_sdc;itchy03_sdd;itchy04_sdb;itchy04_sdc;itchy04_sdd Disks in file system
--perfileset-quota no Per-fileset quota enforcement
-A yes Automatic mount option
-o none Additional mount options
-T /gpfs2 Default mount point
--mount-priority 0 Mount priority
# mmlsconfig
Configuration data for cluster phoenix_scratch.lcg.cscs.ch:
-----------------------------------------------------------
myNodeConfigNumber 126
clusterName phoenix_scratch.lcg.cscs.ch
clusterId 7846265090610531627
autoload no
uidDomain lcg.cscs.ch
dmapiFileHandleSize 32
minReleaseLevel 3.5.0.11
pagepool 2G
[itchy03,itchy04]
pagepool 64G
[itchy01,itchy02,scratchy01,scratchy02,scratchy03,scratchy04]
pagepool 32G
[common]
nsdbufspace 50
maxFilesToCache 50000
maxMBpS 10000
maxblocksize 4096K
cipherList AUTHONLY
subnets 148.187.64.0/gpfs.lcg.cscs.ch
minMissedPingTimeout 60
sendTimeout 60
tokenMemLimit 4G
nsdMaxWorkerThreads 36
restripeOnDiskFailure yes
adminMode central
File systems in cluster phoenix_scratch.lcg.cscs.ch:
----------------------------------------------------
/dev/phoenix_scratch
Upgrade
You will have to create an updated package whenever the kernel changes as GPFS does not use DKMS. Please update the GPFS repo once the RPM has been created.cd /usr/lpp/mmfs/src make LINUX_DISTRIBUTION=REDHAT_AS_LINUX Autoconfig make World make rpm rpm -ivh /root/rpmbuild/RPMS/x86_64/gpfs.gplbin-*.rpm modprobe mmfs26
Nagios
mmaddcallbackGPFS provides a command mmaddcallback that will trigger user defined commands when certain GPFS events occur. The list of events that can be used as triggers are fully documented within the man page. The following list consists of global events that can be used as triggers to give you an idea of what is achievable. It should be trivial to build some passive nagios checks for these.
afmFilesetExpired
Triggered when the contents of a fileset expire either as a result of the fileset being disconnected for the expiration timeout value or when the fileset is marked as expired using the AFM administration commands.
afmFilesetUnexpired
Triggered when the contents of a fileset become unexpired either as a result of the reconnection to home or when the fileset is marked as unexpired using the AFM administration commands.
nodeJoin
Triggered when one or more nodes join the cluster.
nodeLeave
Triggered when one or more nodes leave the cluster.
quorumReached
Triggered when a quorum has been established in the GPFS cluster. This event is triggered only on the elected cluster manager node, not on all the nodes in the cluster.
quorumLoss
Triggered when a quorum has been lost in the GPFS cluster.
quorumNodeJoin
Triggered when one or more quorum nodes join the cluster.
quorumNodeLeave
Triggered when one or more quorum nodes leave the cluster.
clusterManagerTakeover
Basic mmaddcallback example
The following is a basic example of triggering an event upon a node leaving a cluster. /apps is available to all nodes.cat /apps/monitoring/test.sh #!/bin/bash echo $(hostname): is about to shutdown | logger -t gpfs_callback mmaddcallback test --command /apps/monitoring/test.sh --event preShutdown -N scratchy01.lcg.cscs.ch mmaddcallback: Propagating the cluster configuration data to all affected nodes. This is an asynchronous process.Now lets test
date; mmshutdown Mon Mai 5 15:05:10 CEST 2014 Mon Mai 5 15:05:11 CEST 2014: mmshutdown: Starting force unmount of GPFS file systems Mon Mai 5 15:05:16 CEST 2014: mmshutdown: Shutting down GPFS daemons Shutting down! 'shutdown' command about to kill process 3834 Unloading modules from /lib/modules/2.6.32-431.5.1.el6.x86_64/extra Unloading module mmfs26 Unloading module mmfslinux Unloading module tracedev Mon Mai 5 15:05:21 CEST 2014: mmshutdown: Finished # From /var/log/messages 2014-05-05T15:05:16.133663+02:00 scratchy01 gpfs_callback: scratchy01.lcg.cscs.ch: is about to shutdown
Ganglia
Useful ganglia charts are shown in: http://ganglia.lcg.cscs.ch/ganglia/?r=hour&cs=&ce=&tab=v&vn=GPFS2Oct 31 14:55 [root@wn01:~]# echo io_s | mmpmon -s mmpmon node 148.187.65.1 name wn01 io_s OK timestamp: 1383227732/587764 bytes read: 27845668669 bytes written: 19746297868 opens: 56460 closes: 55757 reads: 13513 writes: 10478999 readdir: 7276233 inode updates: 837741For command line usage you can use the following to gather interactive metrics, these counters are relative.
Oct 31 14:54 [root@wn01:~]# gpfs_getio_s.ksh Started: Thu Oct 31 14:54:21 CET 2013 Sample Interval: 2 Seconds Timestamp ReadMB/s WriteMB/s F_open f_close reads writes rdir inode 1383227663 0.0 0.0 0 0 0 0 0 0 1383227665 0.0 0.0 0 0 0 0 0 0For metrics there is a script (/opt/cscs/libexec/gmetric-scripts/gpfs/gpfs_stats.sh) that is run every minute that feeds data to ganglia. Some notes about mmpmon
- Timestamps are in EPOCH
- When using an input file (-i flag) the separator for options is a newline
- You can use fs_io_s rather than io_s to gather per filesystem metrics useful if you mount more than one GPFS filesystem on a host
GPFS Policies
On server nodesitchy04.lcg.cscs.ch there is a cron job that runs a cleanup GPFS policy every two days at 0:04am:
4 0 */2 * * [ -e /usr/local/bin/apply_gpfs_policy.bash ] && [ -e /usr/local/etc/gpfs2wipe.policy ] && /usr/local/bin/apply_gpfs_policy.bash /usr/local/etc/gpfs2wipe.policyThe important files are these:
-
/usr/local/bin/apply_gpfs_policy.bash#! /bin/bash NODES=$(hostname) POLICY=$1 FILESYSTEM="phoenix_scratch" SHAREDIR="/gpfs2/gpfspolicytmpdir" CMD="/usr/lpp/mmfs/bin/mmapplypolicy" LOG="/var/log/GPFS-policy.log.$$" subject="[phoenix] GPFS policies report" email="root@localhost" cc="storage-alert@cscs.ch" START=$(date) mkdir -p ${SHAREDIR} if [ ! -d "$SHAREDIR" ]; then echo "Shared directory $SHAREDIR does not exist, cannot continue." exit -1 fi if [ ! -s "$POLICY" ]; then echo "Policy file $POLICY does not exist, cannot continue." exit -1 fi ${CMD} ${FILESYSTEM} -I yes -P ${POLICY} -g ${SHAREDIR} -s ${SHAREDIR} -f ${SHAREDIR} -A 23 -a 4 -n 12 -m 12 -q -N ${NODES} --choice-algorithm fast &> ${LOG} END=$(date) mailbody=$(mktemp /tmp/policiesemail.XXXXXXXXXX) # by echoing to stdout, we will get an email ( echo "--------------------" echo "GPFS Policies Report" echo "--------------------" echo echo "Running on: $(hostname -f)" echo "Policy file: ${POLICY}" echo "Policy contents: $(cat ${POLICY})" echo "Start time: ${START}" echo "Finish time: ${END}" echo echo "Below is the actual GPFS policy report" echo echo "======================================" echo ) > ${mailbody} grep -v -E 'Policy execution|entries scanned|Policy evaluation|Sorting.*file list records' ${LOG} >> ${mailbody} echo >> ${mailbody} echo "======================================" >> ${mailbody} cat ${mailbody} | mail -s "${subject}" -c ${cc} ${email} rm -f ${mailbody} -
/usr/local/etc/gpfs2wipe.policyRULE 'gpfs2wipe' DELETE FROM POOL 'data' WHERE (PATH_NAME like '/gpfs2/scratch/%' OR PATH_NAME like '/gpfs2/gridhome/%') AND ( CURRENT_TIMESTAMP - MODIFICATION_TIME > INTERVAL '5' DAYS )
Other notes
Adding extra metadata servers to GPFS2
NOTE: These operations were carried out on 13.05.2015 This document explains the steps required to add two new metadata serversitchy03.lcg.cscs.ch and itchy04.lcg.cscs.ch to Phoenix's GPFS filesystem.
These two nodes are similar hardware to the other metadata servers in this GPFS cluster (IBM x3650M3), being the size of the SSDs available different: 200GB in previous systems vs. 400GB in the new ones.
*NOTE*: The document assumes that a base configuration, consisting on at least the following steps is done:
-
NTPis properly configured. -
SSH keysare properly shared and it's possible to do passwordless all-to-all ssh communication. SSH agents must not be required to do this communication. - Configuration is consistent and won't be overwritten by configuration management tools. Usually this means that all necessary changes have been commited to the configuration management tool.
Fix /etc/hosts
This is a temporary fix that is required ONLY until all nodes are installed via the same configuration management tool (Puppet).
# ssh root@itchy01.lcg.cscs.ch
# export OLD_SERVERS="itchy01.lcg.cscs.ch,itchy02.lcg.cscs.ch,scratchy01.lcg.cscs.ch,scratchy02.lcg.cscs.ch,scratchy03.lcg.cscs.ch,scratchy04.lcg.cscs.ch"
# export NEW_SERVERS="itchy03.lcg.cscs.ch,itchy04.lcg.cscs.ch"
# mmdsh -N ${OLD_SERVERS} 'echo "10.10.64.37 itchy04.mngt" >> /etc/hosts'
# mmdsh -N ${OLD_SERVERS} 'echo "10.10.64.36 itchy03.mngt" >> /etc/hosts'
# mmdsh -N ${NEW_SERVERS} 'echo "10.10.64.30 scratchy01-a" >> /etc/hosts'
# mmdsh -N ${NEW_SERVERS} 'echo "10.10.64.31 scratchy02-a" >> /etc/hosts'
# mmdsh -N ${NEW_SERVERS} 'echo "10.10.64.32 scratchy03-a" >> /etc/hosts'
# mmdsh -N ${NEW_SERVERS} 'echo "10.10.64.33 scratchy04-a" >> /etc/hosts'
# mmdsh -N ${NEW_SERVERS} 'echo "10.10.64.34 itchy01-a" >> /etc/hosts'
# mmdsh -N ${NEW_SERVERS} 'echo "10.10.64.35 itchy02-a" >> /etc/hosts'
# grep -E '[wn|cream|arc].*.10' /etc/hosts > /tmp/foo
# scp /tmp/foo itchy03:/tmp/foo
# scp /tmp/foo itchy04:/tmp/foo
# mmdsh -N ${NEW_SERVERS} 'cat /tmp/foo >> /etc/hosts'
Add the nodes to GPFS
# export GPFS_NODES="itchy03.lcg.cscs.ch,itchy04.lcg.cscs.ch"
# mmaddnode -N ${GPFS_NODES}
# mmchlicense server --accept -N ${GPFS_NODES}
# mmstartup -N ${GPFS_NODES}
# mmgetstate -N ${GPFS_NODES}
Configure them properly
# mmchconfig pagepool=64G -i -N ${GPFS_NODES}
# mmchnode --admin-interface=itchy03.mngt -N itchy03.lcg.cscs.ch
# mmchnode --admin-interface=itchy04.mngt -N itchy04.lcg.cscs.ch
# mmchnode --manager --nonquorum -N ${GPFS_NODES}
Add the new NSDs & Disks
Contents ofnew_nsd_12.05.15.conf %nsd: nsd=itchy03_sdb device=/dev/sdb failureGroup=10 usage=metadataOnly pool=system servers=itchy03 %nsd: nsd=itchy03_sdc device=/dev/sdc failureGroup=10 usage=metadataOnly pool=system servers=itchy03 %nsd: nsd=itchy03_sdd device=/dev/sdd failureGroup=10 usage=metadataOnly pool=system servers=itchy03 %nsd: nsd=itchy04_sdb device=/dev/sdb failureGroup=11 usage=metadataOnly pool=system servers=itchy04 %nsd: nsd=itchy04_sdc device=/dev/sdc failureGroup=11 usage=metadataOnly pool=system servers=itchy04 %nsd: nsd=itchy04_sdd device=/dev/sdd failureGroup=11 usage=metadataOnly pool=system servers=itchy04
# mmcrnsd -F ./new_nsd_12.05.15.conf # mmadddisk phoenix_scratch -F ./new_nsd_12.05.15.conf
Update MaxInodes/AllocInodes per fileset
Originally the filesystem had this:# mmlsfileset phoenix_scratch -L Filesets in file system 'phoenix_scratch': Name Id RootInode ParentId Created InodeSpace MaxInodes AllocInodes Comment root 0 3 -- Mon Oct 6 16:40:47 2014 0 1000128 1000128 root fileset gridhome 1 1048579 0 Mon Oct 6 16:41:18 2014 1 30000000 30000000 scratch 2 67108867 0 Thu Apr 16 08:41:07 2015 2 100000000 100000000And these are the new values:
# mmchfileset phoenix_scratch scratch --inode-limit 330000000:330000000 # mmchfileset phoenix_scratch gridhome --inode-limit 50000000:50000000
Update quotas
Originally the filesystem had this:# mmrepquota -j phoenix_scratch
Block Limits | File Limits
Name type KB quota limit in_doubt grace | files quota limit in_doubt grace
root FILESET 15180992 0 0 0 none | 14 0 0 0 none
gridhome FILESET 160512 0 0 1509056 none | 203531 20000000 25000000 1365 none
scratch FILESET 480671456 0 0 23914944 none | 2415975 95000000 95000000 47946 none
Now we need to adapt these values to the new calculations:
# export QUOTA_scratch="330000000"
# export QUOTA_gridhome="45000000"
# mmsetquota -j gridhome --inode_hardquota ${QUOTA_gridhome} --inode_softquota ${QUOTA_gridhome} phoenix_scratch
# mmsetquota -j scratch --inode_hardquota ${QUOTA_scratch} --inode_softquota ${QUOTA_scratch} phoenix_scratch
| ServiceCardForm | |
|---|---|
| Service name | GPFS2 |
| Machines this service is installed in | itchy[0-1],scratchy[0-4] |
| Is Grid service | No |
| Depends on the following services | |
| Expert | Miguel Gila |
| CM |
Puppet |
| Provisioning | Razor |


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
GPFS2_schema.png | r1 | manage | 153.3 K | 2014-03-10 - 10:37 | MiguelGila |
Topic revision: r25 - 2015-05-20 - MiguelGila

{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback