Service Card for LRMS
- Service Card for LRMS
- Definition
- Operations
- New set up with SLURM 15.08
- Set up
- SLURM control daemon and DBD hosts (slurm1 & slurm2)
- Partitions & Reservations
- Prolog/Epilog/JobSubmission script
- Node health checking
- Job preemption/checkpointing
- Accounting & Fairshare
- QoS settings to increase Job Scheduling Priority
- Dependencies (other services, mount points, ...)
- Backup
- Installation
- Upgrade
- Monitoring
- Manuals
- Issues
Definition
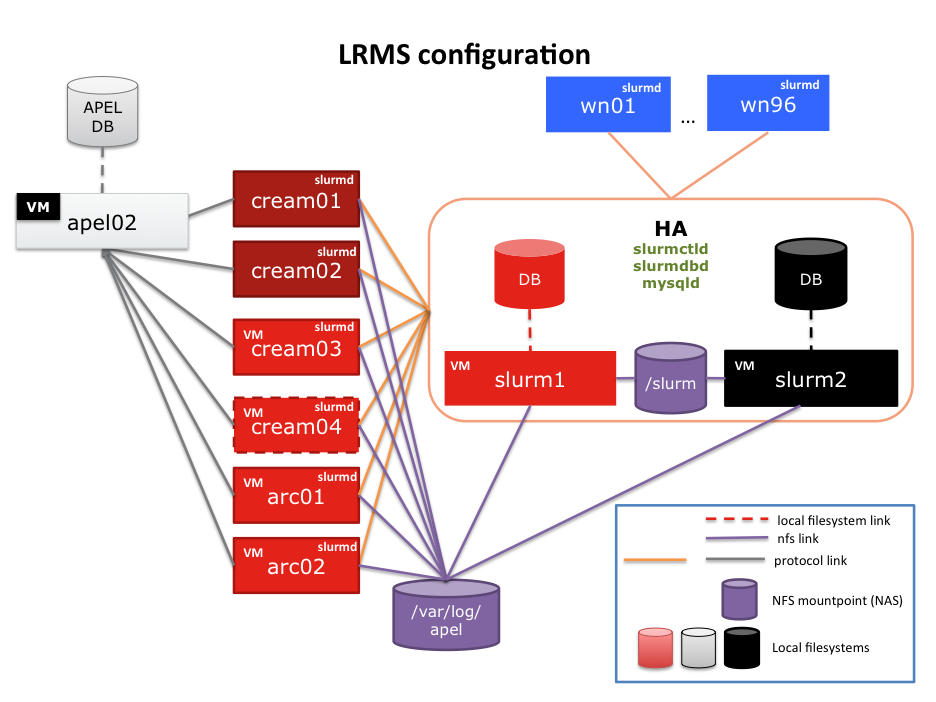
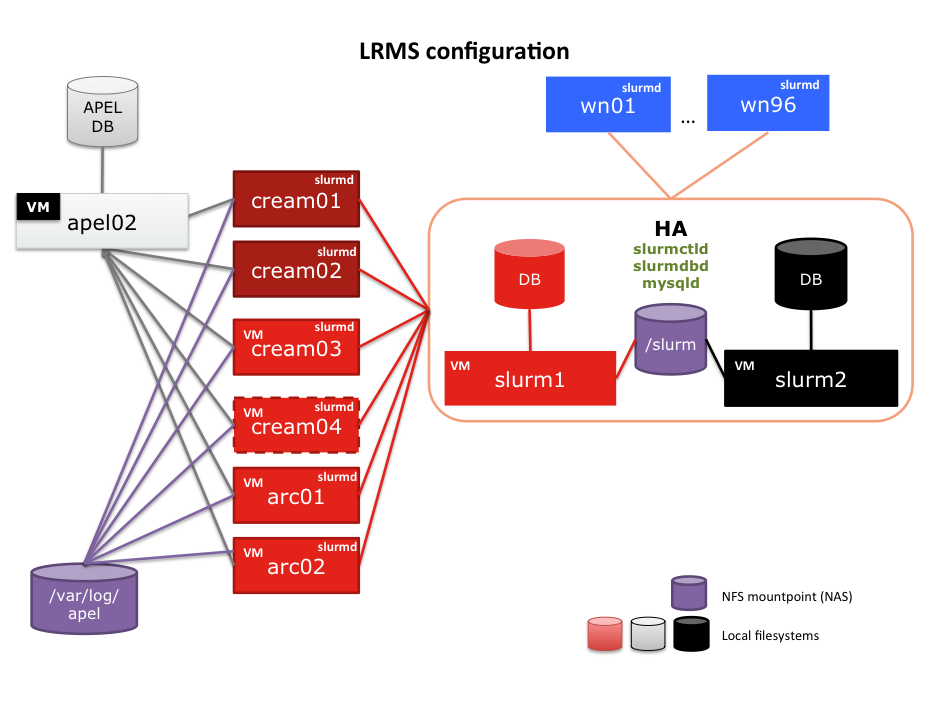
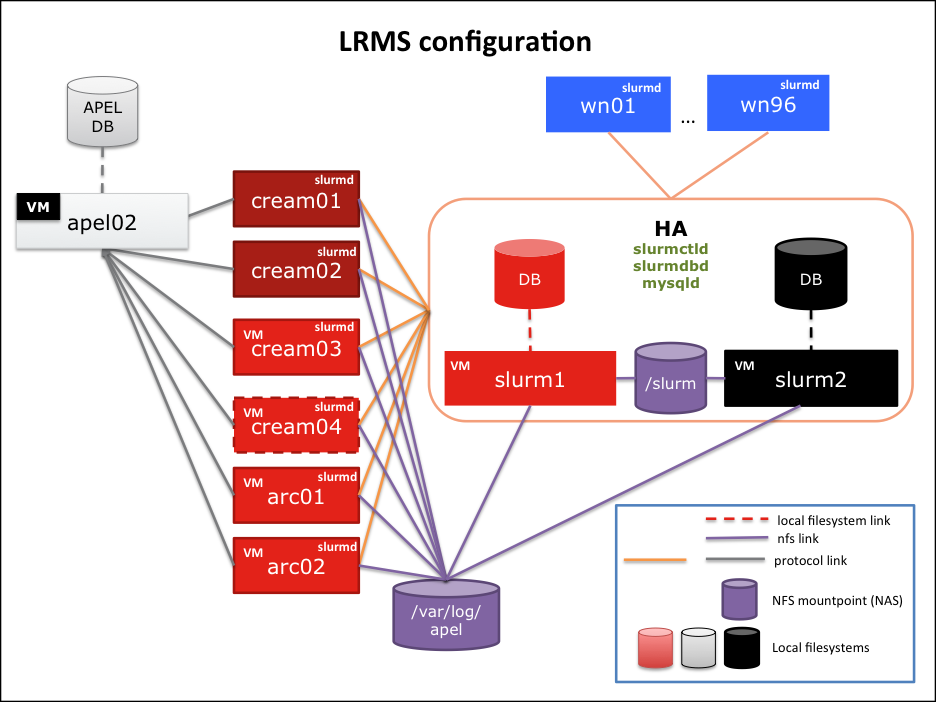 SLURM is the cornerstone of job submission. It's a piece of software that needs to run all the time and it is configured as follows:
SLURM is the cornerstone of job submission. It's a piece of software that needs to run all the time and it is configured as follows: - SLURM control daemon (
slurmctld) runs onslurm1(main) andslurm2(backup). - SLURM DB daemon (
slurmdbd) runs onslurm1andslurm2 - MySQL daemon (
mysqld) runs onslurm1andslurm2 - SLURM daemon (
slurmd) runs on all CREAM and ARC CEs as well as on the WNs. - MUNGE runs on every machine where there is a slurm process running. The key is configured via CFengine and is located in
/etc/munge/munge.key - APEL 4 (EMI-3) parser is running on all CREAM-CEs, but it does not push accounting data anywhere (yet).
Operations
Client tools
These commands are executed from any node runningslurmd or slurmctld -
squeueShows the current status of the queues of the system. -
scontrol show partitionsandscontrol show resshow the partitions and reservations available. -
sacctis used to show the accounting configuration of the system. -
sacctmgris used to manage the accounting of the system. -
sviewruns a graphical interview similar to squeue -
sshareshows the sharing and priority numbers. -
export SQUEUE_FORMAT="%6i %8u %7a %.14j %.9P%.3t %.10r %.12S %.12e %.10L %.10l %.5D %.9N %.12p %.5m %.12v"modifies the behaviouir of squeue to show more detailed information about the queue.- If you do not specify a number the column will not be truncated
-
scrontrol pingtells you the status of the control daemons. -
scontrol show configshows the configuration running. Withscontrol reconfiguresome changes made toslurm.confcan be applied to the running system without restarting any daemon. - How to list the accounts (groups) on the accounting database:
sacctmgr show accounts - How to list the accounting tree with all fields (fairshare):
sacctmgr show association tree |less
Accounting commands
- Calculate the efficiency of all jobs for a certain account on a month NOT WORKING:
sacct -X -n -p -A prd_cms,prd_atlas,lhcb -s cd -S 2014-01-01T00:00 -E 2014-02-01T00:00 -o CPUTimeRAW,Elapsed |awk -F'|' '{n=split($2, t, "[-:]"); sum1+=$1; sum2+=t[n-3]*24*60*60+60*60*t[n-2]+60*t[n-1]+t[n]}; END{print sum1, sum2}' | awk '{printf "%f\n",($2/$1)*100} - Number of CPUs (now):
scontrol show no -o |grep 'NodeName=wn' | awk 'match($0,/CPUTot=[0-9]+/) {print substr($0,RSTART,RLENGTH)}' | awk -F= '{total=total + $2} END {print "Number of CPUs: " total} - Number of jobs OK
sacct -X -n -p -s cd -S 2013-10-01T00:00 -E 2013-11-01T00:00 |wc -l
- Total number of jobs
sacct -X -n -p -s cd,ca,f,nf,to,s -S 2013-12-01T00:00 -E 2014-01-01T00:00 |wc -l
- Wall time hours
sreport cluster utilization Start=2013-09-01T00:00 End=2013-10-01T00:00 -t hour -P -n | awk -F'|' '{print "Number of used CPU hours: "$2}' - Wall time hours ARC
sreport cluster AccountUtilizationByUser Start=2014-01-01T00:00 End=2014-02-01T00:00 -t hour -P -n |grep nordu | awk -F'|' '{sum1+=$5} END {print "Number of used CPU hours: "sum1} - Number of production jobs
sacct -X -n -p -A prd_cms,prd_atlas,lhcb -s cd -S 2013-09-01T00:00 -E 2013-10-01T00:00 |wc -l
- Get the Avg. time in queue for a series of jobs:
/usr/bin/sacct -n --ncpus=8-64 -X -r atlas,atlashimem -S 2014-01-01T00:00 -E 2014-05-01T00:00 --format=JobID,JobName,NCPU,Comment,Elapsed,CpuTime,cputimeraw,State,Account,Eligible,Start,End > /tmp/file_jobs.txt awk -F '\n' '{print $1}' /tmp/file_jobs.txt | awk '{cmd="date --date=\""$10"\" +\"%s\" "; cmd | getline eligibledate; close(cmd); cmd1="date --date=\""$11"\" +\"%s\" "; cmd1 | getline startdate; print startdate-eligibledate; close(cmd1)}' | grep -v '-' | awk '{sum+=$1} END { S=sum/NR; printf "Average: %dh:%dm:%ds\n",S/(60*60),S%(60*60)/60,S%60}' rm /tmp/file_jobs.txt - Efficiency of each job for a given period:
sacct -S 2014-06-25T00:00 -E 2014-06-26T00:00 --format=jobid,jobname,totalcpu,cputime -s completed -p -n |grep -v batch | awk -F '|' '{print $1"|"$2"|"$3"|"$4}' | sed 's/\([0-9][0-9]:\)\([0-9][0-9]\)\.[0-9]*/00:\1\2/g' | sed 's/\(^[0-9][0-9]:[0-9][0-9]:[0-9][0-9]\)/0:\1/g' | sed 's/\(|\)\([0-9][0-9]:[0-9][0-9]:[0-9][0-9]\)/|0:\2/g' | sed 's/\([0-9][0-9]:[0-9][0-9]:\)00/\101/g ' | sed 's/-/:/g' | awk -F'[:|]' '{totalcpusecs=($3*24*60*60)+($4*60*60)+($5*60)+$6; cputimesecs=($7*24*60*60)+($8*60*60)+($9*60)+$10; eff=(totalcpusecs/cputimesecs)*100; printf "jobid=%s, jobname=%s, totalcpu=%s, totalcpu(s)=%d, cputime=%s, cputime(s)=%d | efficiency=%d\%\n", $1, $2, ($3*24)+$5":"$5":"$6, totalcpusecs, ($7*24)+$8":"$9":"$10, cputimesecs,eff}' - Average efficiency of a period:
sacct -S 2014-06-25T00:00 -E 2014-06-26T00:00 --format=jobid,jobname,totalcpu,cputime -s completed -p -n | grep -v batch | awk -F '|' '{print $1"|"$2"|"$3"|"$4}' | sed 's/\([0-9][0-9]:\)\([0-9][0-9]\)\.[0-9]*/00:\1\2/g' | sed 's/\(^[0-9][0-9]:[0-9][0-9]:[0-9][0-9]\)/0:\1/g' | sed 's/\(|\)\([0-9][0-9]:[0-9][0-9]:[0-9][0-9]\)/|0:\2/g' | sed 's/\([0-9][0-9]:[0-9][0-9]:\)00/\101/g ' | sed 's/-/:/g' | awk -F'[:|]' '{totalcpusecs=($3*24*60*60)+($4*60*60)+($5*60)+$6; cputimesecs=($7*24*60*60)+($8*60*60)+($9*60)+$10; eff+=(totalcpusecs/cputimesecs)*100; count+=1} END {totaleff=eff/count; printf "Average efficiency: %f\% \n", totaleff}'
- Calculating all-jobs efficiency on a specific month:
# sacct -S 2014-06-01T00:00 -E 2014-07-01T00:00 \ --format=jobid,jobname,totalcpu,cputime -s completed \ -p -n >> /tmp/jobscompleted_efficiency.June14.log # cat /tmp/jobscompleted_efficiency.June14.log \ | grep -v batch | awk -F '|' '{print $1"|"$2"|"$3"|"$4}' \ | sed 's/\([0-9][0-9]:\)\([0-9][0-9]\)\.[0-9]*/00:\1\2/g' \ | sed 's/\(^[0-9][0-9]:[0-9][0-9]:[0-9][0-9]\)/0:\1/g' \ | sed 's/\(|\)\([0-9][0-9]:[0-9][0-9]:[0-9][0-9]\)/|0:\2/g' \ | sed 's/\([0-9][0-9]:[0-9][0-9]:\)00/\101/g ' \ | sed 's/-/:/g' \ | awk -F'[:|]' '{totalcpusecs=($3*24*60*60)+($4*60*60)+($5*60)+$6; \ cputimesecs=($7*24*60*60)+($8*60*60)+($9*60)+$10; \ eff=(totalcpusecs/cputimesecs)*100;if (eff > 100) eff2+=100; else eff2+=eff; count+=1} \ END {totaleff=eff2/count; printf "Average efficiency: %f\% \n", totaleff}'
Job states
Quoting the man page ofsacct (http://slurm.schedmd.com/sacct.html-
CACANCELLED: Job was explicitly cancelled by the user or system administrator. The job may or may not have been initiated. -
CDCOMPLETED: Job has terminated all processes on all nodes. -
CFCONFIGURING: Job has been allocated resources, but are waiting for them to become ready for use (e.g. booting). -
CGCOMPLETING: Job is in the process of completing. Some processes on some nodes may still be active. -
FFAILED: Job terminated with non-zero exit code or other failure condition. -
NFNODE_FAIL: Job terminated due to failure of one or more allocated nodes. -
PDPENDING: Job is awaiting resource allocation. -
PRPREEMPTED: Job terminated due to preemption. -
RRUNNING: Job currently has an allocation. -
RSRESIZING: Job is about to change size. -
SSUSPENDED: Job has an allocation, but execution has been suspended. -
TOTIMEOUT: Job terminated upon reaching its time limit.
Testing
A very quick way to test the system is to submit a job directly using SLURM commands (either as root or as a regular user). Here are some examples:# su - dteam082 -bash-4.1$ srun -p cscs --reservation=priority_jobs -n1 /bin/hostname wn65.lcg.cscs.ch # srun -n1 -p other hostname srun: job 631791 queued and waiting for resources srun: job 631791 has been allocated resources wn79.lcg.cscs.chAnother way of testing a node is by using reservations. Look at this example:
# scontrol create reservation=maintenance starttime=NOW duration=UNLIMITED accounts=dteam,root partitionname=cscs flags=maint,ignore_jobs nodes=wn11 # scontrol show res ReservationName=priority_jobs StartTime=2013-10-24T16:29:13 EndTime=2014-10-24T16:29:13 Duration=365-00:00:00 Nodes=wn65,wn73 NodeCnt=2 CoreCnt=64 Features=(null) PartitionName=(null) Flags=IGNORE_JOBS,SPEC_NODES Users=(null) Accounts=ops,dteam Licenses=(null) State=ACTIVE ReservationName=maintenance StartTime=2014-02-26T10:54:03 EndTime=2015-02-26T10:54:03 Duration=365-00:00:00 Nodes=wn11 NodeCnt=1 CoreCnt=32 Features=(null) PartitionName=cscs Flags=MAINT,IGNORE_JOBS,SPEC_NODES Users=(null) Accounts=dteam,root Licenses=(null) State=ACTIVEThis allows us to run a job on the specified node(s) while blocking other jobs from running there:
# srun -n1 -p cscs --reservation=maintenance hostname wn11.lcg.cscs.ch
Start/stop procedures
The following services can be started/stopped using standard commands:-
slurmdcan be started/stopped at any time on the WNs since job status is not modified when the daemons go down. -
slurmctldcan be started/stopped also at any time, as long as one of the two servers running this daemon is active. -
slurmdbdcan be started/stopped also at any time, as long as one of the two servers running this daemon (andmysqld) is active.
Checking logs
-
slurmdlogs are in/var/log/slurmd.log -
slurmctldlogs are in/var/log/slurmctld.log -
slurmdbdlogs are in/varlog/slurmdbd.log - Extra logs from CREAM-CE parsing (apel parser actually) are in
/var/log/apel/slurm.acc.YYYYMMDD. This directory is a NAS mount.
High Availability
SLURM is configured in Active/Passive mode on two nodes:-
slurm1is the main controller (slurmctld) and main DB node (slurmdbd+mysqld). -
slurm2runs the same configuration asslurm1and is configured to failover if the main controller dies.
# scontrol ping Slurmctld(primary/backup) at slurm1/slurm2 are UP/UP
Adding/removing nodes (WNs/CEs) to the cluster
- Modify
slurm.confinCFengineand push changes everywhere.- If you remove nodes, make sure they are not in any reservation or there will be problems with
slurmctld. - If you add nodes, make sure CE nodes are not included in any partition and that WN nodes are included in all the partitions.
- If you remove nodes, make sure they are not in any reservation or there will be problems with
- Reconfigure slurm from
slurm1orslurm2with# scontrol reconfigure
New set up with SLURM 15.08
- Accounts get created at the SLURMDBD level using CSCS accounting scripts:
/apps/fojorina/system/opt/slurm_accounting/bin]:-)$ sudo ./populate_slurmdb.pl --facility=PHOENIX --cluster=phoenix --execute
- Then, fairhsare is assigned as follows:
$ sudo sacctmgr update account atlas where cluster=phoenix set fairshare=33 $ sudo sacctmgr update account cms where cluster=phoenix set fairshare=33 $ sudo sacctmgr update account lhcb where cluster=phoenix set fairshare=33 $ sudo sacctmgr update user atlas01,atlas02,atlas04,atlas05,atlasplt,atlasprd,atlassgm where cluster=phoenix set fairshare=parent $ sudo sacctmgr update user cms01,cms02,cms03,cms04,cms05,cmsplt,cmsprd,cmssgm where cluster=phoenix set fairshare=parent $ sudo sacctmgr update user lhcb01,lhcb02,lhcb03,lhcb04,lhcb05,lhcbplt,lhcbprd,lhcbsgm where cluster=phoenix set fairshare=parent
Set up
The main configuration file for SLURM is installed on/etc/slurm/slurm.conf on all the nodes belonging to the SLURM cluster. This is where most of the configuration is defined, except for the reservation configuration, which is done live.
The SLURMDBD configuration is on /etc/slurm/slurmdbd.conf and the MySQL configuration is on /etc/my.cnf.
SLURM control daemon and DBD hosts (slurm1 & slurm2)
These two machines are standard Scientific Linux 6.x systems with very little grid middleware installed on them (basically just enough to create the users). The DBD daemon needs access to a MySQL database configured in master-slave as seen in MySQLReplication. Additional configuration needs to be done, note the following steps need to be performed on both MySQL servers.mysql -p #Replace __PASSWORD__ with the actual password. GRANT ALL ON slurm_acct_db.* TO 'slurm'@'localhost' IDENTIFIED BY '__PASSWORD__'; GRANT ALL ON slurm_acct_db.* TO 'slurm'@'slurm1' IDENTIFIED BY '__PASSWORD__'; GRANT ALL ON slurm_acct_db.* TO 'slurm'@'slurm2' IDENTIFIED BY '__PASSWORD__';Once this is done, the following steps need to be done to ensure the accounting works.
sacctmgr add cluster CSCS-LCG2
Partitions & Reservations
- The file
slurm.confmust include all the partitions that we need to run jobs from all users:#------------------------------------------------------------------------------- # COMPUTE NODES #------------------------------------------------------------------------------- #Controls how a node's configuration specifications in slurm.conf are used. # 0 - use hardware configuration (must agree with slurm.conf) # 1 - use slurm.conf, nodes with fewer resources are marked DOWN # 2 - use slurm.conf, but do not mark nodes down as in (1) FastSchedule=1 # Use the 'DEFAULT' NodeName to set default values for the cluster nodes #NodeName=DEFAULT RealMemory=64359 CoresPerSocket=8 Sockets=2 ThreadsPerCore=2 State=UNKNOWN NodeName=DEFAULT RealMemory=64359 CPUs=32 State=UNKNOWN NodeName=wn[01-48] State=UNKNOWN NodeName=wn[50] State=UNKNOWN NodeName=wn[52-79] State=UNKNOWN NodeName=cream0[3-4] RealMemory=15949 CPUs=6 NodeName=cream0[1-2] RealMemory=64273 CPUs=16 NodeName=arc0[1-2] RealMemory=8192 CPUs=6 [...] #-------------------------------------------------------------------------------------- #PARTITION SETTING #-------------------------------------------------------------------------------------- # default values for all partitions # # Commented out because if DefaultTime is not set, the MaxTime is chosen (which depends on the Partition). #PartitionName=DEFAULT Nodes=ppwn02,ppwn04 Default=YES DefaultTime=01:00:00 Shared=yes Priority=10 PartitionName=DEFAULT Nodes=wn[01-48],wn50,wn[52-79] Default=YES Priority=10 DefMemPerCPU=2000 Shared=NO #Shared=FORCE:1 #Shared=yes PartitionName=cscs Priority=80 MaxTime=24:00:00 AllowGroups=dteam MaxMemPerCPU=2000 Default=NO PartitionName=atlas Priority=10 MaxTime=96:00:00 AllowGroups=atlas,nordugrid DefMemPerCPU=2000 MaxMemPerCPU=4000 Default=NO PartitionName=atlashimem Priority=10 MaxTime=96:00:00 AllowGroups=atlas,nordugrid MaxMemPerCPU=4000 Default=NO PartitionName=cms Priority=10 MaxTime=72:00:00 AllowGroups=cms MaxMemPerCPU=2000 Default=NO PartitionName=lhcb Priority=10 MaxTime=120:00:00 AllowGroups=lhcb MaxMemPerCPU=2000 Default=NO PartitionName=lcgadmin Priority=500 MaxTime=24:00:00 AllowGroups=ops,atlas,hone,cms,lhcb,dteam MaxMemPerCPU=2000 Default=NO PartitionName=other Priority=10 MaxTime=36:00:00 AllowGroups=dteam,hone MaxMemPerCPU=2000 Default=YES PartitionName=ops Priority=1000 MaxTime=04:00:00 AllowGroups=ops MaxMemPerCPU=2000 Default=NO
As you can see, CEs are not in any partition and WNs are in all partitions.
- The reservation for
cscsandopsis called priority_jobs and is defined as follows:scontrol create reservation starttime=now duration=infinite nodes=wn65,wn73 reservation=priority_jobs account=ops,dteam flags=ignore_jobs
This means that there have been configured 64 cores reserved on two nodes, wn65 and wn74 for dteam and ops. The CEs automatically select the reservation according to the username the job will run as. These two nodes are also used for the GPFS cleanup policies, which run periodically and for longs periods of time, so not a lot of CPU is wasted here.
- It is a good practice to check for idle nodes to be dedicated (fully or partially) to a reservation, otherwise they cannot be included in the definition of the reservation:
sinfo -N | grep idle
- A reservation cannot be deleted if there are running jobs belonging to it. This can be checked in this way:
squeue -A <reservation_name>
- After defining the new reservation(s) it is useful to check there are no errors
scontrol show res tail -f /var/log/slurmctld.log
Prolog/Epilog/JobSubmission script
A few files are configured to be executed every time is run:TaskProlog=/etc/slurm/TaskProlog.sh TaskEpilog=/etc/slurm/TaskEpilog.sh [...] # required for APEL and CREAM JobCompType=jobcomp/script JobCompLoc=/usr/share/apel/slurm_acc.shAt the time of writing these lines, the prolog and epilog files are empty and are simply configured to allow quick modifications without reconfiguration. The
slurm_acc.sh file gets executed every time a job finishes and writes accounting information to a file so the apel parser can process it.
Node health checking
There is a script that runs periodically (at the same time, as root) in all the WNs and that checks the status of the WN:#------------------------------------------------------------------- # NODE HEALTH #------------------------------------------------------------------- HealthCheckInterval=180 HealthCheckProgram=/etc/slurm/nodeHealthCheck.shThis generates a log
/var/log/nodehealthcheck.log that is log rotated every week.
This script also runs a passive nagios check. This will either show as OK or show the reason why the node is draining. The relevant line is as follows
echo $(hostname),Slurm status,2,${REASON} | send_nsca nagios.lcg.cscs.ch -c /etc/nagios/send_nsca.cfg -d ','
If you need to put a node offline be use to put the keyword ADMIN in the reason to ensure the node is not automatically put back online.
scontrol update node wn45 state=DRAIN reason="ADMIN node as problem that needs investigating"
Why is a node down?
The sinfo command had a '-R' option which will list the reason of why a node is not is a serving statesinfo -R REASON USER TIMESTAMP NODELIST ADMIN blackhole dete root 2014-10-27T10:35:18 wn[31,88] ADMIN blackhole dete root 2014-10-27T10:30:20 wn86 ADMIN blackhole dete root 2014-10-27T10:50:18 wn87
Putting a node back online
It is recommended that you do not return a node to service by using setting it's state to 'RESUME'. Rather remove the 'ADMIN' keyword or simply remove the reason field on the node to allow the node health check to mark the node as back online.Job preemption/checkpointing
Job Preemption and checkpointing are NOT enabled. The scheduler is configured as follows:AuthType=auth/munge SchedulerType=sched/backfill SelectType=select/cons_res SelectTypeParameters=CR_CPU_Memory TaskPlugin=task/none ProctrackType=proctrack/linuxproc
Accounting & Fairshare
Note: When adding accounts/users ensure sacctmgr returns listing the associations that will be created. If this does not appear you likely need to specify the partition. This is the schema of the accounting tree: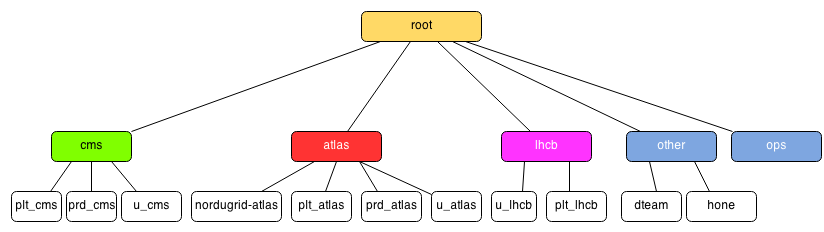 The process to create the accounts is this:
The process to create the accounts is this: - Accounts:
## Partition other sacctmgr add account other Description="Partition other" Organization="none" MaxJobs=200 sacctmgr add account dteam Description="dteam accounts" Organization="dteam" parent=other sacctmgr add account hone Description="hone accounts" Organization="hone" parent=other ## Partition lcgadmin sacctmgr add account ops Description="ops accounts" Organization="OPS" sacctmgr add account lcgadmin Description="SGM accounts" Organization="SGM" ## Partition cms sacctmgr add account cms Description="cms accounts" Organization="CMS" sacctmgr add account u_cms Description="cms user accounts" Organization="CMS" parent=cms fairshare=4 # CMS users get 4% of the cluster sacctmgr add account plt_cms Description="cms PILOT accounts" Organization="CMS" parent=cms fairshare=16 # CMS PILOT jobs get 16% of the cluster sacctmgr add account prd_cms Description="cms PRD accounts" Organization="CMS" parent=cms fairshare=20 # CMS PRD jobs a get 20% of the cluster ## Partition atlas sacctmgr add account atlas Description="ATLAS accounts" Organization="ATLAS" sacctmgr add account u_atlas Description="atlas USER accounts" Organization="ATLAS" parent=atlas fairshare=4 # ATLAS users get 4% of the cluster sacctmgr add account plt_atlas Description="atlas PILOT accounts" Organization="ATLAS" parent=atlas fairshare=18 # ATLAS PILOT jobs get 18% of the cluster sacctmgr add account prd_atlas Description="atlas PRD accounts" Organization="ATLAS" parent=atlas fairshare=18 # ALAS PRD jobs get 18% of the cluster ## Partition lhcb sacctmgr add account lhcb Description="LHCb accounts" Organization="LHCb" sacctmgr add account u_lhcb Description="lhcb USER accounts" Organization="LHCb" parent=lhcb fairshare=2 # LHCb user jobs get 2% of the cluster sacctmgr add account plt_lhcb Description="lhcb PILOT accounts" Organization="LHCb" parent=lhcb fairshare=18 # LHCb pilot jobs get 18% of the cluster
- Users
### Add OPS accounts sacctmgr add user $(echo $(for user in $(grep '^ops' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=ops DefaultAccount=ops Partition=lcgadmin sacctmgr add user $(echo $(for user in $(grep '^ops' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=ops DefaultAccount=ops Partition=ops sacctmgr add user nordugrid-atlas Parent=u_atlas DefaultAccount=u_atlas Partition=atlas,atlashimem ### Add SGM accounts (partition lcgadmin) sacctmgr add user atlassgm Parent=lcgadmin DefaultAccount=lcgadmin Partition=lcgadmin,atlas,atlashimem sacctmgr add user cmssgm Parent=lcgadmin DefaultAccount=lcgadmin Partition=lcgadmin,cms sacctmgr add user lhcbsgm Parent=lcgadmin DefaultAccount=lcgadmin Partition=lcgadmin,lhcb sacctmgr add user dteamsgm Parent=lcgadmin DefaultAccount=lcgadmin Partition=lcgadmin sacctmgr add user opssgm Parent=lcgadmin DefaultAccount=lcgadmin Partition=lcgadmin ### Add HONE accounts (partition other) sacctmgr add user $(echo $(for user in $(grep '^hone' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=hone DefaultAccount=hone Partition=other ### Add CMS accounts sacctmgr add user $(echo $(for user in $(grep '^chcms[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_cms DefaultAccount=u_cms Partition=cms fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^cms[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_cms DefaultAccount=u_cms Partition=cms fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^cmsplt[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=plt_cms DefaultAccount=plt_cms Partition=cms fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^prdcms[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=prd_cms DefaultAccount=prd_cms Partition=cms fairshare=parent ### Add ATLAS accounts sacctmgr add user $(echo $(for user in $(grep '^chatlas[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_atlas DefaultAccount=u_atlas Partition=atlas,atlashimem fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^atlas[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_atlas DefaultAccount=u_atlas Partition=atlas,atlashimem fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^atlasplt' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=plt_atlas DefaultAccount=plt_atlas Partition=atlas,atlashimem fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^atlasprd' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=prd_atlas DefaultAccount=prd_atlas Partition=atlas,atlashimem fairshare=parent sacctmgr add user nordugrid-atlas Parent=u_atlas DefaultAccount=u_atlas Partition=atlas,atlashimem fairshare=parent ### Add LHCb accounts sacctmgr add user $(echo $(for user in $(grep '^lhcb[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_lhcb DefaultAccount=u_lhcb Partition=lhcb fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^chlhcb[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_lhcb DefaultAccount=u_lhcb Partition=lhcb fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^lhcbprd[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=u_lhcb DefaultAccount=u_lhcb Partition=lhcb fairshare=parent sacctmgr add user $(echo $(for user in $(grep '^lhcbplt[0-9]' /etc/passwd | awk -F: '{print $1}'); do echo -n "$user,"; done)|sed '$s/.$//') Parent=plt_lhcb DefaultAccount=plt_lhcb Partition=lhcb fairshare=parent ### Add DTEAM user accounts sacctmgr add user dteam044,dteam001,dteam002,dteam003,dteam004,dteam005,dteam006,dteam007,dteam008,dteam009,dteam010,dteam011,dteam012,dteam013,dteam014,dteam015,dteam016,dteam017,dteam018,dteam019,dteam020,dteam021,dteam022,dteam023,dteam024,dteam025,dteam026,dteam027,dteam028,dteam029,dteam030,dteam031,dteam032,dteam033,dteam034,dteam035,dteam036,dteam037,dteam038,dteam039,dteam040,dteam041,dteam042,dteam043,dteam045,dteam046,dteam047,dteam048,dteam049,dteam050,dteam051,dteam052,dteam053,dteam054,dteam055,dteam056,dteam057,dteam058,dteam059,dteam060,dteam061,dteam062,dteam063,dteam064,dteam065,dteam066,dteam067,dteam068,dteam069,dteam070,dteam071,dteam072,dteam073,dteam074,dteam075,dteam076,dteam077,dteam078,dteam079,dteam080,dteam081,dteam082,dteam083,dteam084,dteam085,dteam086,dteam087,dteam088,dteam089,dteam090,dteam091,dteam092,dteam093,dteam094,dteam095,dteam096,dteam097,dteam098,dteam099,dteam100,dteamprd,dteamsgm Parent=dteam DefaultAccount=dteam Partition=other,cscs
- Pseudo-QoS: With SLURM QoS policies can be defined, but considering current requirements, a simple policy setting the max number of jobs running on the system should suffice. In this way, each VO has a max of N jobs running, so if one VO does 'crazy-submission', there will still be enough slots for other VOs.
sacctmgr update account cms set grpJobs=1500 sacctmgr update account atlas set grpJobs=1500 sacctmgr update account lhcb set grpJobs=1500 sacctmgr update account ops set grpJobs=20 sacctmgr update account where account=lcgadmin set MaxJobs=4096
QoS settings to increase Job Scheduling Priority
Quality of Service (QoS) settings can be used inslurm to increase the priority for a given set of jobs. Please keep in mind that job scheduling priority is evaluated by slurm considering several factors and the priority set through QoS is just one of them: figuring out which is the right value to be used in production may require some experimentation.
First of all make sure that the following option is enable in slurm.conf
PriorityType=priority/multifactorand then in the same file define an appropriate value for
PriorityWeightQOS=1000 # may need several attemptsreconfigure
slurm as usual
# scontrol reconfigThen define a QoS in this way
# sacctmgr create qos name=cmspilot priority=10 # same hereand set it for a user typing
# sacctmgr modify user cmsplt21 set qos=cmspilotto check that the configuration has been implemented correctly you can run:
# sacctmgr show user where user=cmsplt21 WithASSOCplease note that assigning a QoS to a user in this way implies for that user to have only one
qos defined: that qos automatically becomes her default one. If you need to modify an already existing QoS just use
# sacctmgr modify qos name=cmspilot set priority=20
Dependencies (other services, mount points, ...)
LRMS depends on:- NFS mount points from the NAS
-
/slurmserves bothslurmctlddaemons to sync JobIDs and job statusnas.lcg.cscs.ch:/ifs/LCG/shared/slurm on /slurm type nfs
-
/var/log/apelserves the apel accounting pluginnas.lcg.cscs.ch:/ifs/LCG/shared/apelaccounting on /var/log/apel type nfs
-
- MySQL daemon running on local partitions on
slurm1andslurm2
Backup
SLURM gets backed up using the backup scripts inCFengine. Three proceses are executed: - A dump of the MySQL DB of
slurmdbdis created every day on/root/mysqldump_slurm_acct_db.sql.gz. - A dump of the SLURM accounting tree is created every day on
/root/sacctmgr.dump. - These two files get copied to
/storeafter being generated. On both machines,slurm1andslurm2.
Installation
The following configuration is already inCFengine, but it's kept here for reference.
- Both nodes need to be part of GPFS and have /home/wlcg pointing to the right place:
- /home/nordugrid-atlas-slurm -> /gpfs/home/nordugrid-atlas-slurm
- /home/wlcg -> /gpfs/home/wlcg
- /tmpdir_slurm -> /gpfs/tmpdir_slurm
-
slurm[1-2]: These packages are pulled from Phoenix repo:slurm-munge slurm slurm-slurmdbd slurm-sql slurm-plugins munge-libs munge-devel munge emi-release-3.0.0 emi-slurm-utils glite-yaim-slurm-utils
- Run YAIM to configure the users:
/opt/glite/yaim/bin/yaim -s /opt/cscs/siteinfo/site-info.def -n SLURM_utils -c /opt/glite/yaim/bin/yaim -s /opt/cscs/siteinfo/site-info.def -r -f config_users
Upgrade
- Stop
slurmd,slurmctldandslurmdbdeverywhere in this order. - Yum update the packages
^*slurm*in the following order:- Head nodes
- SLURMD nodes (CEs and WNs).
- Start
slurmdbd,slurmctldandslurmdin this order.
Monitoring
Nagios
- In SLURM head nodes (
slurm1&slurm2) a few nagios checks are defined:- Daemon proceses running.
- MySQL replication process status.
- In nodes with
slurmdrunning, a simple daemon process status is run.
Ganglia
- In SLURM the following gmetric scripts run (cron job
/etc/cron.d/CSCS_ganglia):- The script
/opt/cscs/libexec/gmetric-scripts/slurm/slurm_jobs.shpublishes to ganglia the general statistics of number of jobs running. - The script
/opt/cscs/libexec/gmetric-scripts/slurm/perf_jobs_R_PD_perVO.bashpublishes to ganglia detailed statistics of jobs running and pending per VO (account in SLURM terms). - The script
/opt/cscs/libexec/gmetric-scripts/slurm/perf_jobs_F_CA_TO_NF_perVO.bashpublishes to ganglia summarised statistics of the number of jobs failed VO (account in SLURM terms) AND detailed statistics about these same jobs in terms of reason for the failure.
- The script
- In GANGLIA, the cron job
/etc/cron.d/CSCS_custom_graphsruns a process that generates the fancy graphs seen in the monoverview page.*/5 * * * * root /opt/cscs/libexec/ganglia-custom-graphs/graph_jobs_R_PD_perVO.bash -c /etc/phoenix-slurm-graphs.cfg */5 * * * * root /opt/cscs/libexec/ganglia-custom-graphs/graph_jobs_TotalFailed_perVO.bash -c /etc/phoenix-slurm-graphs.cfg
Basically what it does is create a few graphs merging together statistics from different RRDs (pending and running per VO) for one machineslurm1
Other
Manuals
Issues
General troubleshooting
If you have made a change that for some reason isn't working do a full restart (not reconfig) of the control daemon and possibly the database daemon if necessary. Why? Because both the control and database daemons store state in memory as well as referring to the on disk database. Depending on which s* command you use you are either querying in memory state (srun, squeue, sbatch) or on disk state in the db (sacct, sacctmgr). This can lead to odd situations where you update an account or user and srun shows errors saying that the combination of account/ partition is invalid when it shouldn't be. It has been seen in other production systems when moving users to different accounts that a full restart of the control and database daemons were needed despite everything looking good in sacctmgr.Jobs fail with the reason NODE_FAILURE but the node is up
Check the control daemon logs to see if slurm is rejecting the node. In our case the memory available was below the expected amount as the kernel had been upgraded and reserved more memory.[2014-04-07T15:47:58.091] error: Node wn45 has low real_memory size (64358 < 64359) [2014-04-07T15:47:58.092] error: Setting node wn45 state to DOWNOur nodehealth script saw no issues and marked the node back online. This meant the node would accept more work and then jobs would be canceled with the reason NODE_FAILURE. The solution is to not define the node memory to such a precise value.
Compute node fails to register with slurm control daemon
- Check the date on the machine, NTP is likely out of sync
- Check the MTU
- Check that munge is running
| ServiceCardForm | |
|---|---|
| Service name | LRMS |
| Machines this service is installed in | slurm[1,2],phoenix4[1,2] |
| Is Grid service | Yes |
| Depends on the following services | NAS |
| Expert | Miguel Gila |
| CM | CfEngine |
| Provisioning | Razor |


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
slurm_accounting_tree-2.png | r1 | manage | 22.0 K | 2013-11-17 - 20:28 | MiguelGila | SLURM accounting tree |
| |
slurm_cfg_schema.png | r3 r2 r1 | manage | 183.1 K | 2013-11-17 - 18:02 | MiguelGila | SLURM LRMS configuration |
Topic revision: r62 - 2016-03-25 - MiguelGila

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback